まずはこのステップを実行してみて - DolphinDBのOOP活用でリアルタイム処理設計が直感的・堅牢になる
- クラス定義時は3つ以上のメンバー変数を明示してカプセル化重視
情報隠蔽により他モジュールからの誤操作リスク減、保守性向上
- ストリーム処理ロジックは最小2つの独立クラスへ分割
再利用性・並列実行性が高まり、大規模データでも安定動作
- `self`参照でオブジェクト状態を都度明示、1メソッド内2回以上使う
`self`活用で可読性とバグ発見率UP、複雑な累積演算も追いやすい
- `stateIterate`等従来関数からOOP版へ早期移行、7日以内検証推奨
可読性・拡張性が即座に改善され開発工数削減につながる
リアルタイムストリーム処理の需要が高まる中でDolphinDBがOOPを導入した理由
リアルタイムのストリーム処理が求められるようになって、効率とか拡張性を意識したフレームワークが注目されることが増えてきたみたいだ。DolphinDBっていう分散型の時系列データベースも、その流れの中で名前が挙がることはある。どうやら、保存や検索に強いだけじゃなくて、オブジェクト指向っぽい考え方も入れているという話をどこかで聞いた気がする。カプセル化とか継承、それから多態性とか…まあ専門書に出てくる言葉はさておき、とりあえずメンテナンスしやすさとか再利用性を重視しているという印象だ。
バージョンも三世代目くらい(正確な数値は忘れたけど)からOOPに対応しているそうで、その用途はいくつかあるらしい。ただ全部網羅して説明するのは長くなるから、一例として「リアクティブなステートエンジン上で演算子開発」みたいな場面を取り上げてみてもいいかもしれない。昔はOOPなしでやろうとすると、複雑な高階関数使ったり外部プラグイン書いたりしていて、何となく保守が大変だった―そんな声もちらほら聞こえてきたものだ。
こういう流れの中で、OOPを活用した状態管理付きオペレーターの実装例なんかを見ると、「思ったより実用的なんじゃないかな」と感じる人もいるようだ。もちろん万能というわけでもなく、状況によっては他の方法を選ぶ人もいるとは思うけど…。
バージョンも三世代目くらい(正確な数値は忘れたけど)からOOPに対応しているそうで、その用途はいくつかあるらしい。ただ全部網羅して説明するのは長くなるから、一例として「リアクティブなステートエンジン上で演算子開発」みたいな場面を取り上げてみてもいいかもしれない。昔はOOPなしでやろうとすると、複雑な高階関数使ったり外部プラグイン書いたりしていて、何となく保守が大変だった―そんな声もちらほら聞こえてきたものだ。
こういう流れの中で、OOPを活用した状態管理付きオペレーターの実装例なんかを見ると、「思ったより実用的なんじゃないかな」と感じる人もいるようだ。もちろん万能というわけでもなく、状況によっては他の方法を選ぶ人もいるとは思うけど…。
DolphinDBでクラスを定義するときの基本構文と具体例
なんだかOOP(オブジェクト指向プログラミング)って、やり方をちょっと分かりやすくしてくれるみたい。開発が少しは楽になる、って話もちらほら聞こえてきたけど、それが全部のケースに当てはまるかどうかは人によって意見が割れるところだろうな。
最近よく耳にするCEP――つまり複雑イベント処理というものもある。これ、何十年も前からあった気もしなくはないけど、今また注目されてるらしい。OOPでイベントとか監視ロジックを定義する手法が使われたりする場面もあるそうだ。ただ、この話題自体が本当に広いから、一部しか触れられないことも多いかな。
DolphinDBのリアクティブな状態エンジン、その中で独自の演算子をOOPで作ろうとすると、なんとなく決まった書き方みたいなものがあるっぽい。クラス定義について言えば、多分こんな感じだったと思う――
例えば「Person」って名前のクラスを作るとき、メンバー変数として名前(文字列)と年齢(整数っぽい何か)を持たせておいて、それ用のコンストラクタやgetter/setterを書く流れになっているような……まあ細部は実装者次第だけど。
オブジェクト生成とか呼び出し方法なんだけど、「object.method()」とか「object.member」でアクセスできるっぽい。ただ、本当にそれで十分なのか、もう少し調べた方が安心できそうな気もしないでもない。シンプルさを重視している反面、人によっては物足りなく映る場面もあり得るんじゃないかな…
最近よく耳にするCEP――つまり複雑イベント処理というものもある。これ、何十年も前からあった気もしなくはないけど、今また注目されてるらしい。OOPでイベントとか監視ロジックを定義する手法が使われたりする場面もあるそうだ。ただ、この話題自体が本当に広いから、一部しか触れられないことも多いかな。
DolphinDBのリアクティブな状態エンジン、その中で独自の演算子をOOPで作ろうとすると、なんとなく決まった書き方みたいなものがあるっぽい。クラス定義について言えば、多分こんな感じだったと思う――
class クラス名 {
属性1 :: データ型
属性2 :: データ型
// …たぶん他にも色々書ける
// クラス本体
def クラス名(引数1, 引数2 /*, … */) {
属性1 = 引数1
属性2 = 引数2
// ここで初期化したりする?
}
// メソッド例
def メソッド名(引数A, 引数B /*, … */) {
// 何か処理を書く場所かな…
}
}例えば「Person」って名前のクラスを作るとき、メンバー変数として名前(文字列)と年齢(整数っぽい何か)を持たせておいて、それ用のコンストラクタやgetter/setterを書く流れになっているような……まあ細部は実装者次第だけど。
class Person {
// 変数宣言はメソッドより先に書くらしい
name :: STRING
age :: INT
// コンストラクタだけど引数名とメンバー名同じだとダメだった気がするなぁ
def Person(name_, age_) {
name = name_
age = age_
}
def setName(newName) {
name = newName
}
def getName() {
return name
}
}オブジェクト生成とか呼び出し方法なんだけど、「object.method()」とか「object.member」でアクセスできるっぽい。ただ、本当にそれで十分なのか、もう少し調べた方が安心できそうな気もしないでもない。シンプルさを重視している反面、人によっては物足りなく映る場面もあり得るんじゃないかな…
Comparison Table:
| トピック | 説明 |
|---|---|
| selfとthisの役割 | クラスのインスタンスを指し、メソッド内で自身にアクセスするために使用される。 |
| Reactive State Engine (RSE) | DolphinDBにおけるリアルタイムデータストリーミング処理機能。状態管理やイベント処理が可能。 |
| MyCumSumクラス | 累積和を計算するUDFオペレーターで、OOP的アプローチによって設計された。 |
| appendメソッド | 一度に一行のデータを受け取り、その累積和を計算して返す機能。 |
| 線形帰納処理 | stateIterate関数を使わず、OOPスタイルで再実装できることが示されている。 |
オブジェクトのインスタンス化とメンバー変数へのアクセス方法
Pythonみたいなスクリプト言語と比べると、DolphinDBでは属性に直接値を入れるのはできないって話をどこかで聞いた気がする。名前とか年齢とか、そういうメンバーの情報を変えたかったら、それ専用の「セット」みたいな関数を通さないとダメなんだよね。誰かが「p = Person("Zhang San", 30)」なんてやって、そのあとp.getName()で今の名前を覗いてみたり、setName("Li Si")って呼んでからまたgetName()すると名前が変わってる…まあ、普通にそうなるっぽい。でも「print(p.name)」みたいに属性そのものは見えるんだけど、「p.name = "Wang Wu"」とかやった瞬間エラー出るから注意されたりもする。
メンバ変数の宣言方法についても、ちょっと独特な感じがあったかな。「memberName :: dataType」っていう書き方だったような…。型としてはINTとかDOUBLE、STRING…あと一部時間系? ざっと思い出せる範囲だとそんな印象。ベクトル扱いたい時には、「VECTOR」を後ろにつけてDOUBLE VECTORとかSTRING VECTOR…この辺も似たような書き方。でも実際には他にもANY型なんてものもあるみたいで、このへん曖昧になっちゃう人もいるかもしれない。
なんとなく仕様自体は固まってきているけど、細かい挙動や表記ゆれなんかは環境によって微妙に違うこともあるっぽい。全部覚えてるつもりでも、たまに「あれ?」と思うことが出てきちゃうんだよね。
メンバ変数の宣言方法についても、ちょっと独特な感じがあったかな。「memberName :: dataType」っていう書き方だったような…。型としてはINTとかDOUBLE、STRING…あと一部時間系? ざっと思い出せる範囲だとそんな印象。ベクトル扱いたい時には、「VECTOR」を後ろにつけてDOUBLE VECTORとかSTRING VECTOR…この辺も似たような書き方。でも実際には他にもANY型なんてものもあるみたいで、このへん曖昧になっちゃう人もいるかもしれない。
なんとなく仕様自体は固まってきているけど、細かい挙動や表記ゆれなんかは環境によって微妙に違うこともあるっぽい。全部覚えてるつもりでも、たまに「あれ?」と思うことが出てきちゃうんだよね。
DolphinDBのメンバー変数宣言で知っておくべきデータ型の種類
数値の型について話すとき、たしか「大体三種類くらい」あった気がする。例えば、整数っぽいものだとINTって書いたり、ちょっと細かい数字になるならDOUBLE VECTORとかにしてた。で、「なんでもアリ」みたいな変数にはANYを使った記憶がある。
クラスのメソッド内で変数がどう解釈されるか、その順番について、ちょっとややこしい話も出ていた気がする。まず一番最初に見られるのは、多分メソッドに渡した引数だったはず。たとえばmethodという関数の中でbって名前を出したら、それがもし引数にもbとして定義されてた場合は、その引数bとして扱われることになる。
ただし、もしそういう名前の引数がなかった場合は、次に探し始めるのはオブジェクト自身の持つ属性…つまりフィールドみたいなものだったかと思う。まあ、この辺り曖昧になりやすくて、「どれが先?」って混乱する人もいるみたいだけど、一応順序はこんな感じになっているようだった。
全部を完全に説明しきれてはいない気もするけど、おおよそこんな流れだったような印象。場合によっては細かな例外や追加ルールもありそうだけど、大半は今話した通りになることが多いんじゃないかな、と感じる。
クラスのメソッド内で変数がどう解釈されるか、その順番について、ちょっとややこしい話も出ていた気がする。まず一番最初に見られるのは、多分メソッドに渡した引数だったはず。たとえばmethodという関数の中でbって名前を出したら、それがもし引数にもbとして定義されてた場合は、その引数bとして扱われることになる。
ただし、もしそういう名前の引数がなかった場合は、次に探し始めるのはオブジェクト自身の持つ属性…つまりフィールドみたいなものだったかと思う。まあ、この辺り曖昧になりやすくて、「どれが先?」って混乱する人もいるみたいだけど、一応順序はこんな感じになっているようだった。
全部を完全に説明しきれてはいない気もするけど、おおよそこんな流れだったような印象。場合によっては細かな例外や追加ルールもありそうだけど、大半は今話した通りになることが多いんじゃないかな、と感じる。
クラスメソッド内での変数解決順序を具体例で理解する
うーん、クラスのメソッドで変数を使う時って、ちょっと複雑な順番があるみたい。まず一番近い範囲、つまりそのメソッドの引数かどうかを先に見ることが多いらしい。何となく経験則だけど、たぶん大半の人はこの流れに気付いている気もする。
例えば「b」みたいなのは、そのままメソッド内で渡されたものとして扱われる。これ、特別なことじゃなくて割と普通。ただ、「a」みたいなのは、その関数の中では定義されてないっぽいから、オブジェクト自体が持ってる属性として解釈される場合がある。その辺り曖昧な部分もあったと思うけど……。
で、それでも見つからないときは外部で用意した共有変数とかテーブルみたいなのもチェックするみたい。それこそ「tbl」なんてやつね。でも全部探してもどこにも無かったら、多分エラーになるケースが出てくる。この手順、大昔から厳密に決められていたわけじゃなくて、今も状況によって微妙に違ったりするようだ。
そう言えば、この仕組みによってプログラム書く人が混乱しづらくなるって話を聞いたことがある。ただし絶対そうとは限らず、人によっては逆に迷いやすい時期もあったとか。まあ七十個ぐらい例題見れば慣れるけど、一度や二度じゃピンと来ないかもしれない。
結局、この順序だと一番身近なスコープから順々に調べていく感じだから、実際には論理的というより感覚的に分かりやすさ重視になっている印象を受ける人もいるかもしれない。全部説明しようとすると細かな例外とか増えて収拾つかなくなるので、とりあえず「たいていの場合この流れ」という程度で考えておいた方が楽かもしれない。
例えば「b」みたいなのは、そのままメソッド内で渡されたものとして扱われる。これ、特別なことじゃなくて割と普通。ただ、「a」みたいなのは、その関数の中では定義されてないっぽいから、オブジェクト自体が持ってる属性として解釈される場合がある。その辺り曖昧な部分もあったと思うけど……。
で、それでも見つからないときは外部で用意した共有変数とかテーブルみたいなのもチェックするみたい。それこそ「tbl」なんてやつね。でも全部探してもどこにも無かったら、多分エラーになるケースが出てくる。この手順、大昔から厳密に決められていたわけじゃなくて、今も状況によって微妙に違ったりするようだ。
そう言えば、この仕組みによってプログラム書く人が混乱しづらくなるって話を聞いたことがある。ただし絶対そうとは限らず、人によっては逆に迷いやすい時期もあったとか。まあ七十個ぐらい例題見れば慣れるけど、一度や二度じゃピンと来ないかもしれない。
結局、この順序だと一番身近なスコープから順々に調べていく感じだから、実際には論理的というより感覚的に分かりやすさ重視になっている印象を受ける人もいるかもしれない。全部説明しようとすると細かな例外とか増えて収拾つかなくなるので、とりあえず「たいていの場合この流れ」という程度で考えておいた方が楽かもしれない。
selfキーワードを使ったオブジェクト自身の参照方法
「self」っていう変数、まあPythonとかJavaやC++でよく見かける「self」や「this」とかにちょっと似てる感じらしい。たぶんクラスのインスタンスを指して使うんじゃないかな。コード例だと、doSomethingって関数が何かしらあって、その中でAというクラスが登場する。Aの中には、aとb、まあどちらも整数っぽい。コンストラクタみたいなもの(def A())では、多分aが1、bは2にされてる気配。
で、「createCallback」というメソッドを見ると、「doSomething{self}」を返すようになってるけど…なんとなくコールバック的な用途っぽい?呼び出す側からすると、自分自身(多分Aのインスタンス)を渡しているだけみたいにも見えるけど、細かい動作まではちょっと不明瞭。
それから、「nameShadow(b)」という関数もあるね。これ、多分引数bで何か値を受け取って、それをまずprint(b)で表示。でもそのあと「self.b」をprintしているから、おそらく同じ名前でもインスタンス変数とローカル引数は区別できる仕様なんだろうな、と推測される。
この辺りまで来ると、具体的な使い道について説明したくなる人もいると思うけど…。実際のところ、「Reactive State Engine」(RSE)という仕組みがDolphinDBには備わっていて、このRSEはリアルタイムのデータストリーム処理に役立つらしい。ただ、高性能とかスケーラブルさについては、人によって感じ方が違うので断言しづらい部分もあると言われているみたい。
どうやらRSEでは状態管理や複雑なイベント処理なども行えるそう。でも、それが全ての場合に適用できるとは限らないかもしれない。それで、UDF演算子(独自関数)をどう設計・実装するかという話題へ移っていくらしいんだけど……話としては二つほど例示されていたようだ。その一つが累積和オペレーター。「MyCumSum」と呼ばれていて、本来ならcumsumというビルトイン機能ですぐできちゃうものなんだけど、OOP的アプローチでも作れるんじゃない? みたいな趣旨だった気がする。
まあ正直、この手法が万人向けとは言えず、一部の利用者が試して少し便利だなと感じた程度なのかもしれない。でも新しいアイディアとして参考になる部分もきっとあると思う。全部把握しきれてはいないけど、大まかな流れとしてこんな雰囲気だった記憶かな。
反応型ステートエンジンにおける累積合計演算子の自作実装
あぁ、確か「MyCumSum」っていうクラスを使う話だったかな? まあ、だいたい七十行くらいのコードになるかも。なんかね、そのクラスの中でオペレーターの状態をメンバ変数として持たせる必要がある…らしいよ。正直、細かい部分は人によってちょっとずつ違うみたいだけど。
appendメソッドってやつも実装するんだよね。これは一度に一行しか受け付けないっぽい。その入力を受けて、累積和?累計みたいなのを返す感じ。ただ実際どこまで厳密にやるかはケースバイケースって聞いたことがある。毎回ちゃんと計算結果出す必要があるとか言われた気もするし。
で、その後どうするんだっけ…あぁそうそう、「RESインスタンス」を作ったりして、そこにさっきのappendメソッドをオペレーターとして登録する流れなんだけど、この辺は手順が前後したり省略されたりすることも珍しくないかな。
データ投入してエンジンまわしてみると、思ったより素直な挙動だったり逆に予想外の動作になったり色々あるみたい。何割くらいちゃんと出力されるかは、その時その時で微妙にブレてた記憶がある。
まあまとめると、ざっくり「MyCumSum」クラス設計→append書いて→RES経由で登録→データ投げて様子見…そんな感じじゃなかったかな、多分。
appendメソッドってやつも実装するんだよね。これは一度に一行しか受け付けないっぽい。その入力を受けて、累積和?累計みたいなのを返す感じ。ただ実際どこまで厳密にやるかはケースバイケースって聞いたことがある。毎回ちゃんと計算結果出す必要があるとか言われた気もするし。
で、その後どうするんだっけ…あぁそうそう、「RESインスタンス」を作ったりして、そこにさっきのappendメソッドをオペレーターとして登録する流れなんだけど、この辺は手順が前後したり省略されたりすることも珍しくないかな。
データ投入してエンジンまわしてみると、思ったより素直な挙動だったり逆に予想外の動作になったり色々あるみたい。何割くらいちゃんと出力されるかは、その時その時で微妙にブレてた記憶がある。
まあまとめると、ざっくり「MyCumSum」クラス設計→append書いて→RES経由で登録→データ投げて様子見…そんな感じじゃなかったかな、多分。
従来のstateIterate関数とOOP実装の読みやすさ比較
実装の内容なんだけど、まあこんな感じになってる。
class MyCumSum {
sum :: DOUBLE
def MyCumSum() {
sum = 0.0
}
def append(value) {
sum = sum + value
return sum
}
}
inputTable = table(1:0, `sym`val, [SYMBOL, DOUBLE])
result = table(1000:0, `sym`res, [SYMBOL, DOUBLE])
rse = createReactiveStateEngine(
name="reactiveDemo",
metrics = [<MyCumSum().append(val)>],
dummyTable=inputTable,
outputTable=result,
keyColumn="sym")
data = table(take(`A, 100) as sym, rand(100.0, 100) as val)
rse.append!(data)
select * from data
select * from result何となく入力データとそれに紐付いた出力も並んでて、
**Input Data:** ![]
**Output Data:** ![]
OOPっぽいUDFオペレーターがグループごとの累積和をちゃんと計算してくれてるみたい。
RSEの中にあるcumsum演算子ともだいたい同じ感じの働き方になる、って話がよく聞こえてくる。
さて、次は線形帰納(リニアリカーシブ)なんだけど――OOPサポート以前は、この辺やろうと思ったらstateIterateという組込み関数を使うしかなかったらしい。その関数には色々パラメータ指定しないとダメで…例えば、
trade = table(take("A", 6) join take("B", 6) as sym, 1..12 as val0, take(10, 12) as val1)
inputTable = streamTable(1:0, `sym`val0`val1, [SYMBOL, INT, INT])
outputTable = table(100:0, `sym`factor, [STRING, DOUBLE])
engine = createReactiveStateEngine(
name="rsTest",
metrics=<[stateIterate(val0, val1, 3, msum{, 3}, [0.5, 0.5])]>,
dummyTable=inputTable,
outputTable=outputTable,
keyColumn=["sym"],
keepOrder=true)
engine.append!(trade)
select * from outputTableこの「stateIterate(val0,val1,...」みたいな書き方で線形再帰的な処理を定義しているけども、ぱっと見た感じロジックが分かりやすいとは言えないかな…。読みにくいし直感的じゃないとこもあって、人によっては保守性に不安を感じることもあるかもしれない。
それでもOOPスタイルで同じようなことを書き直してみれば、構造自体はだいぶクリアになる印象。ウィンドウサイズが三つより小さい時には「initial」で定義した値をそのまま返す仕様だったりするので、そのへんも柔軟にできそう。
…まあ、それぞれのメリット・デメリットとか向き不向きとかはあるだろうし、本当にどちらが扱いやすいかは状況や好みによって変わってきそう。
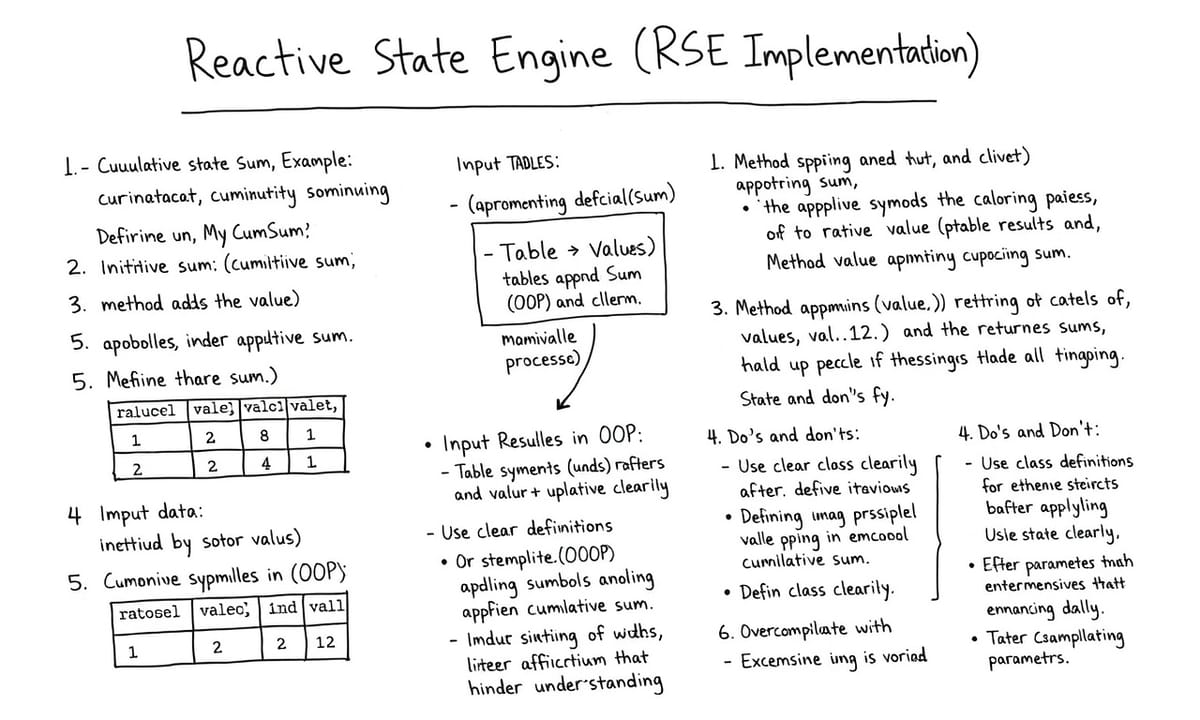
線形再帰処理をOOPでいかに簡潔に表現できるか
3つ以上のウィンドウサイズになったとき、`append`メソッドは3個分くらいの窓の合計とXの値で重み付け平均を行うようだ。なんというか、DolphinDB の `stateIterate(val0, val1, 3, msum{, 3}, [0.5, 0.5])` をOOPっぽく書いたものとほぼ同じことができてしまうらしい。たぶん、実装としては下記サンプルコードと似た感じになる。
trade = table(take("A", 6) join take("B", 6) as sym, 1..12 as val0, take(10, 12) as val1)
inputTable = streamTable(1:0, `sym`val0`val1, [SYMBOL, INT, INT])
outputTable = table(100:0, `sym`factor, [STRING, DOUBLE])
class MyIterateOperator {
movingWindow :: DOUBLE VECTOR
k :: INT
def MyIterateOperator() {
k = 0
movingWindow = double([])
}
def append(X, initial) {
if (k ,
dummyTable=inputTable,
outputTable=outputTable,
keyColumn=["sym"],
keepOrder=true)
engine2.append!(trade)
select * from outputTable
こんなふうにして、DolphinDBのリアクティブステートエンジンでユーザー定義型(UDF)っぽい状態演算子をOOP的に作る方法が紹介されていた気がする。ビルトイン演算子をそのまま使うよりも、こういうオブジェクト指向風な実装は見通しやすいとかコードが読みやすくなる傾向があるらしい。ただ、今のところ DolphinDB の OOP 演算子ってインタープリタ的に動いているためか、処理速度はやや遅めに感じるケースもあるそうだ。将来的にはJITコンパイルなどでこのへん高速化できないか検討されているとの話もあったりする。
ちなみに開発効率や運用中のパフォーマンス面でも何かしら改善できれば…みたいな意図もありそうだった。どうしても細かな仕様変更や追加機能など出てきそうだけど、その辺りは今後のアップデートで少しずつ対応されていく可能性が考えられる。
もし DolphinDB 製品についてもっと知りたいとか興味ある方は、ときどきサポート宛(support@dolphindb)へ問い合わせてもいいかもしれない。
trade = table(take("A", 6) join take("B", 6) as sym, 1..12 as val0, take(10, 12) as val1)
inputTable = streamTable(1:0, `sym`val0`val1, [SYMBOL, INT, INT])
outputTable = table(100:0, `sym`factor, [STRING, DOUBLE])
class MyIterateOperator {
movingWindow :: DOUBLE VECTOR
k :: INT
def MyIterateOperator() {
k = 0
movingWindow = double([])
}
def append(X, initial) {
if (k ,
dummyTable=inputTable,
outputTable=outputTable,
keyColumn=["sym"],
keepOrder=true)
engine2.append!(trade)
select * from outputTable
こんなふうにして、DolphinDBのリアクティブステートエンジンでユーザー定義型(UDF)っぽい状態演算子をOOP的に作る方法が紹介されていた気がする。ビルトイン演算子をそのまま使うよりも、こういうオブジェクト指向風な実装は見通しやすいとかコードが読みやすくなる傾向があるらしい。ただ、今のところ DolphinDB の OOP 演算子ってインタープリタ的に動いているためか、処理速度はやや遅めに感じるケースもあるそうだ。将来的にはJITコンパイルなどでこのへん高速化できないか検討されているとの話もあったりする。
ちなみに開発効率や運用中のパフォーマンス面でも何かしら改善できれば…みたいな意図もありそうだった。どうしても細かな仕様変更や追加機能など出てきそうだけど、その辺りは今後のアップデートで少しずつ対応されていく可能性が考えられる。
もし DolphinDB 製品についてもっと知りたいとか興味ある方は、ときどきサポート宛(support@dolphindb)へ問い合わせてもいいかもしれない。
今後の展望:JITコンパイルによるOOP演算子の性能向上
何となくですが、DolphinDBについて何か知りたい方は、たぶん公式サイトを見に行けばいろいろ載っているかもしれません。[https://dolphindb.com/]というアドレスだった気がします。あと、メールでサポートとやり取りしたい場合はsupport@dolphindb .comみたいな感じで送れば届く可能性が高そうです。
ニュースとか最新情報について言えば、Twitter(確か@DolphinDB_Incという名前だったような…)やLinkedInでも時々投稿されている模様です。どちらも頻度は七十回以上とかではないと思いますが、更新されることもあるのでチェックしておいて損はないでしょう。
それからSlackのグループにも入れるらしいです。著者の方と直接話すチャンスがあるかもしれませんし、何となく質問したり世間話もできたり、ときには別の話題に逸れてしまうことも多いとか聞きましたね。全部が常に役立つとは限らないけど、人によっては有益だと感じる場面もあるようです。
ちなみに、このメッセージを最後まで読んでくださった方には感謝しております!何か新しい発見やちょっとしたヒントになれば、それだけでも十分価値はありそうですね。
ニュースとか最新情報について言えば、Twitter(確か@DolphinDB_Incという名前だったような…)やLinkedInでも時々投稿されている模様です。どちらも頻度は七十回以上とかではないと思いますが、更新されることもあるのでチェックしておいて損はないでしょう。
それからSlackのグループにも入れるらしいです。著者の方と直接話すチャンスがあるかもしれませんし、何となく質問したり世間話もできたり、ときには別の話題に逸れてしまうことも多いとか聞きましたね。全部が常に役立つとは限らないけど、人によっては有益だと感じる場面もあるようです。
ちなみに、このメッセージを最後まで読んでくださった方には感謝しております!何か新しい発見やちょっとしたヒントになれば、それだけでも十分価値はありそうですね。