
負荷テストとは…
負荷テスト、か。…またこの話。正直、面倒なんだよね。でも、やらないと後で地獄を見るのも、知ってる。 リリース後に「サイトが重い」「サーバーが落ちた」とか、もう考えたくもない。
要するに、作ったシステムが、実際のアクセス…それも、一番混雑する時のアクセスに耐えられるか、前もって試しておくこと。 保険みたいなもの、かな。何もないのが一番だけど、何かあった時のために、やっておく。
どうしてやるのか?昔、失敗した話
昔、あるECサイトのキャンペーンで、ひどい目にあったことがある。開始時刻ぴったりに、案の定アクセスが集中して、サーバーが応答しなくなった。いわゆる「鯖落ち」。
あの時の電話の嵐と、機会損失の額を考えたら…。事前に負荷テストをちゃんとしておけば、って、今でも思う。結局、ボトルネックになってたのはDBのクエリだったんだけど、それを突き止めるのに、また時間がかかった。
だから、やる。問題が起きてから対応するのは、本当に大変だから。 特に、原因究明が難しいんだよね、パフォーマンスの問題は。
じゃあ、どうやるの?
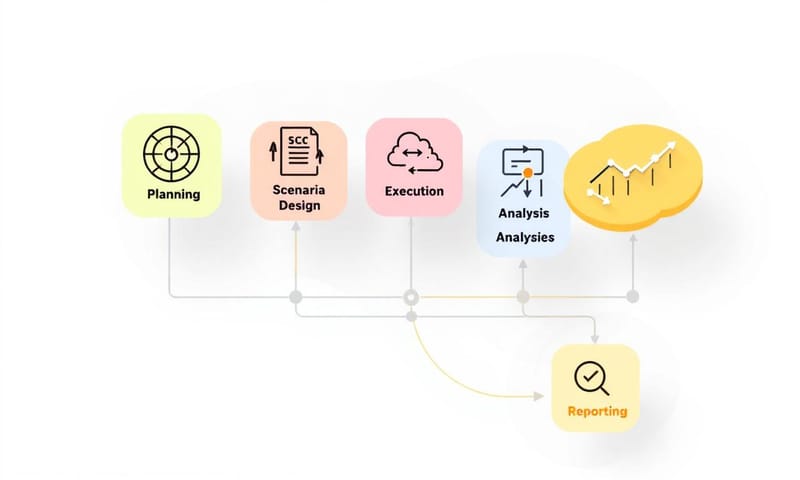
まあ、ざっくりとした流れがある。計画して、準備して、やってみて、結果を見て、対策する。 当たり前だけど、これが難しい。
- 計画:ゴールを決める。
まず、何を達成できれば「合格」なのか決めること。 「同時接続1000人でも、表示速度が3秒以内」とか、具体的な数字で。 漠然と「速くしたい」じゃダメ。 - 設計:シナリオを作る。
ユーザーが実際にどういう操作をするか、想像してシナリオを作る。 みんながトップページだけ見るわけじゃない。ログインして、商品を検索して、カートに入れて、決済する…みたいな、一連の流れ。 このシナリオが現実的じゃないと、テストの意味がない。 - 準備:環境とツールを用意する。
本番と全く同じじゃなくてもいいけど、近い環境を用意する。 ツールは色々ある。昔からあるJMeterとか、最近だとk6とか。 クラウドなら、AWSとかが提供してる負荷テストサービスを使うのも手。 - 実施:負荷をかける。
作ったシナリオをツールに食わせて、実際にアクセスを発生させる。最初は少しずつ負荷を上げていって、どこで限界が来るかを見極めるのが定石。 - 分析と対策:結果を読み解く。
テストが終わったら、集めたデータとにらめっこ。どこが遅いのか、何が原因かを探る。 そして、対策して、またテスト。この繰り返し。
指標は何を見る?
テスト中に見るべき数字はいくつかある。大事なのは、一つの数字だけじゃなくて、全体を見ること。
- レスポンスタイム(応答時間)
これは基本。リクエストを投げてから、反応が返ってくるまでの時間。 でも、平均値だけ見てると騙される。95パーセンタイル値とか、遅い方のリクエストがどうなってるかを見るのが大事。 - スループット
単位時間あたりにさばけるリクエストの数。 RPS (Requests Per Second) とか。これがシステムの処理能力の天井を示す。 - エラーレート
文字通り、エラーになったリクエストの割合。これがゼロじゃない時点で、何か問題が起きてる。 - リソース使用率 (CPU, メモリ)
サーバー側のCPUやメモリがどうなってるか。CPUが100%に張り付いてたら、もう限界。 メモリを使い果たしてたら、もっと危険。
ツールは何を使えばいい?
これも色々あるけど、まあ、代表的なものをいくつか。
| ツール名 | 個人的な所感 |
|---|---|
| Apache JMeter | 古くからある、ザ・定番。 GUIでシナリオ作れるけど、ちょっと古臭い感じは否めない。でも、できることは多い。 |
| k6 (Grafana k6) | 最近のお気に入り。JavaScriptでシナリオを書くのが、開発者には馴染みやすい。 CI/CDに組み込みやすいのも良い。 |
| Gatling | Scalaでシナリオを書く。これも強力。 JMeterよりパフォーマンスが良い、って話も聞く。レポートが綺麗。 |
| Locust | Pythonで書けるのが特徴。 Python使いなら、これが一番とっつきやすいかも。 |
クラウド時代の負荷テスト
昔は物理サーバーのスペックとにらめっこしてたけど、今はクラウドが主流。だから、考え方も少し変わる。
例えば、AWSには「Distributed Load Testing on AWS」っていう、そのものズバリなソリューションがある。 Fargateを使って、サーバーレスで大規模な負荷を発生させられる。 自分たちで負荷用のサーバーを大量に用意しなくていいのは、すごく楽。 ただ、こういうサービスは便利だけど、何が起こってるかブラックボックスになりがちなので、そこは注意が必要かも。
海外のドキュメント、例えばAWSの公式ガイドとかを見ると、こういうマネージドサービスや、もっと進んだ「カオスエンジニアリング」みたいな話によく繋がっていく。 でも、日本の現場だと、まだJMeterで職人芸的に頑張ってるケースも多い印象。 どちらが良い悪いじゃなくて、文化とか、求められるものの違いなんだろうな、と思う。
でも、これって万能じゃない
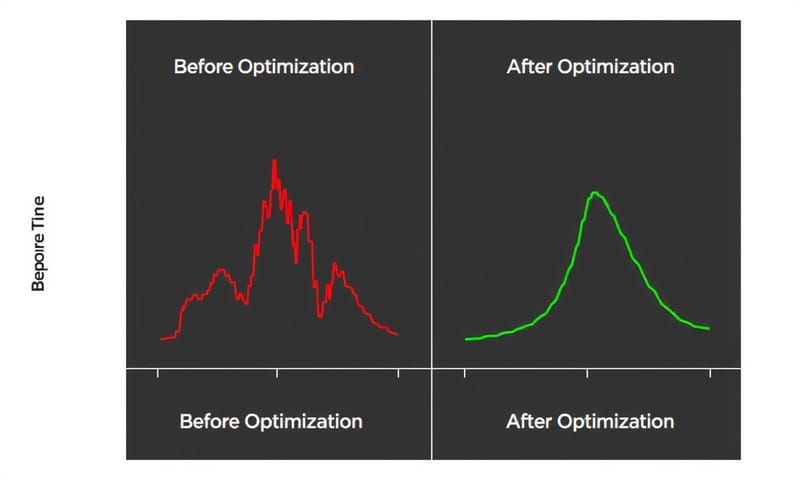
負荷テストで「問題なし」の結果が出ても、それで100%安心はできない。なぜなら、テストはあくまでシミュレーションだから。
作ったシナリオ以外の動きを、実際のユーザーは平気でしてくる。 キャンペーン開始直後に、想定外のページにアクセスが集中するとか。結局、一番の負荷テストは、本番環境そのもの、ということなのかもしれない。
だから、負荷テストは「最低限の保証」を得るためのもの。完璧な未来を予測する水晶玉じゃない。この割り切りは、意外と大事だと思う。
あなたの現場では、負荷テスト、どうしてますか?よかったらコメントで教えてください。


