
最近、OpenTelemetryを触ってて…。これまでELKスタックとかDatadogとか、かれこれ10年近くロギング周りは見てきたけど、今どきの、特にAIとかが絡む世界だと何かないかなって探してたら、CNCFのプロジェクトであるOpenTelemetryが目に入った。
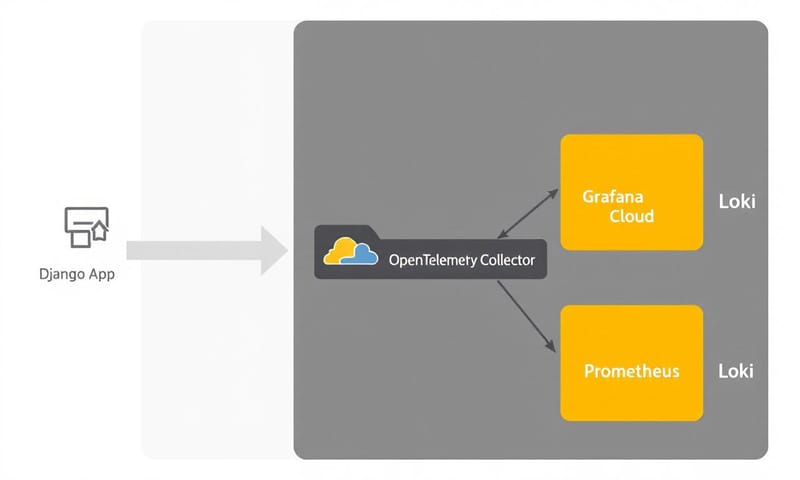
で、触ってみて思ったのは、これ、バックエンドサーバーへの直接的な統合からうまいこと抽象化してくれる層なんだなって。特にサイドカーで動かすと、DatadogとかELKのエージェントみたいな感じで使える。なるほど、と。ログのパイプラインを中央に集めて、好きなインフラに送れる。ELKでもいいし、Prometheus/Loki/Tempoのスタックでもいい。BetterStackとかGrafana Cloudみたいなクラウドサービスでも。だいたい無料枠があるから試せるし。
ただ…うん、ドキュメントがちょっと…散らばってるというか。ChatGPTに聞いても堂々巡りになったりして、正直、イライラした。数日格闘して、ようやくトレースとログがちゃんと追えるようになった設定を、ここにメモしておく。
で、結局これ、何が嬉しいの?
コードを書き換える前に、何がいいのか。要するに「ベンダーロックインからの解放」。これに尽きるかも。
Datadog SDKをコードに埋め込むと、もうDatadogから離れられない。でもOpenTelemetryを挟んでおけば、データの送り先(Exporter)を変えるだけでいい。今日はGrafana、明日はDatadog、みたいなことが理論上は可能。まぁ、そんな頻繁に変えないけど、選択肢があるっていうのが精神的にすごく楽。
あと、トレース、メトリクス、ログ。いわゆる「可観測性の3本柱」を、同じ枠組みで扱えるのも大きい。今まではトレースはX、ログはY、みたいにバラバラになりがちだったから。
具体的な設定、メモっとく
ここからが本題。Djangoで動かすための具体的なファイル設定。順を追って…。
1. asgi.py / wsgi.py: アプリケーションのエントリーポイント
まず、リクエストが最初に来るところ。アプリケーション全体を `OpenTelemetryMiddleware` でラップする。これで、すべてのリクエストが自動的に計装されるようになる。
# asgi.py
import os
from django.core.asgi import get_asgi_application
# from langsmith.middleware import TracingMiddleware # もしLangSmith使うなら
from opentelemetry.instrumentation.asgi import OpenTelemetryMiddleware
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'backend.settings.production')
django_asgi_app = get_asgi_application()
# OpenTelemetryでラップ
application = OpenTelemetryMiddleware(django_asgi_app)
# application = TracingMiddleware(application) # LangSmithも使うならこんな感じ
2. manage.py: 設定の読み込み
次に `manage.py`。コマンドラインからDjangoを操作するときにもOpenTelemetryが動くように、ここで設定ファイルを読み込ませる。`main()` の中で `configure_opentelemetry()` を呼ぶだけ。
#!/usr/bin/env python
import os
import sys
def main():
# ★★★ この行を追加 ★★★
from contrib.otel_config import configure_opentelemetry
configure_opentelemetry()
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'backend.settings')
try:
from django.core.management import execute_from_command_line
except ImportError as exc:
raise ImportError(
"Couldn't import Django. Are you sure it's installed and "
"available on your PYTHONPATH environment variable? Did you "
"forget to activate a virtual environment?"
) from exc
execute_from_command_line(sys.argv)
if __name__ == '__main__':
main()
3. otel_config.py: 計装の心臓部
ここが一番のキモになる `otel_config.py`。トレース、ログ、そしてどのライブラリを計装(instrument)するかを定義するファイル。
公式ドキュメント、正直ちょっと分かりにくい部分があって…。特にExporter周りとか。でも、日本の技術ブログ、例えば[Qiita]とかで具体的な`docker-compose.yml`のサンプルを見つけると、「ああ、なるほど」って繋がることが多い。海外のドキュメントは「概念」、日本の記事は「動くコード」って感じの棲み分けかな、個人的には。
# contrib/otel_config.py
import logging
import os
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# ログ関連のインポート
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
# 計装したいライブラリのInstrumentor
from opentelemetry.instrumentation.django import DjangoInstrumentor
from opentelemetry.instrumentation.logging import LoggingInstrumentor
from opentelemetry.instrumentation.psycopg2 import Psycopg2Instrumentor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
# ...その他必要なものを追加...
_ALREADY = False
def configure_opentelemetry():
global _ALREADY
if _ALREADY:
return
_ALREADY = True
service_name = os.environ.get('OTEL_SERVICE_NAME', 'default-service')
resource = Resource(attributes={"service.name": service_name})
# --- トレースの設定 ---
tp = TracerProvider(resource=resource)
trace.set_tracer_provider(tp)
tp.add_span_processor(
BatchSpanProcessor(OTLPSpanExporter())
)
# --- ログの設定 ---
lp = LoggerProvider(resource=resource)
set_logger_provider(lp)
lp.add_log_record_processor(
BatchLogRecordProcessor(OTLPLogExporter())
)
handler = LoggingHandler(level=logging.INFO, logger_provider=lp)
logging.getLogger().addHandler(handler)
# --- 使ってるライブラリを計装 ---
# 必要なものだけ選べばいい
DjangoInstrumentor().instrument(tracer_provider=tp, is_sql_commentor_enabled=True)
Psycopg2Instrumentor().instrument(tracer_provider=tp, skip_dep_check=True)
LoggingInstrumentor().instrument(tracer_provider=tp, set_logging_format=True)
RequestsInstrumentor().instrument(tracer_provider=tp)
# RedisInstrumentor().instrument(tracer_provider=tp)
# CeleryInstrumentor().instrument() # Celeryは別ファイルで

Docker周り。Collectorがハブになる
ローカル開発では[Docker Compose]を使うのが楽。ポイントは、アプリケーション(Django)のコンテナとは別に `otel-collector` コンテナを立てること。これが「サイドカーモデル」ってやつ。
4. docker-compose.yml: 環境変数とCollectorの定義
全部貼ると長いから、大事なとこだけ抜粋。Djangoのコンテナに `OTEL_...` 系の環境変数を設定して、Collectorの場所を教えてあげる。
# docker-compose.ymlの一部
services:
django:
# ... buildとかvolumesとか ...
environment:
# ... 他の環境変数 ...
- OTEL_SERVICE_NAME=my-django-app
- OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4318 # collectorのサービス名を指定
- OTEL_LOGS_EXPORTER=otlp
depends_on:
- postgres
- otel-collector # collectorが先に起動するように
# ... postgresとかredisとか ...
otel-collector:
image: otel/opentelemetry-collector-contrib:0.102.1 # バージョンは適宜
command: ["--config=/etc/otel-collector-config.yml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yml # 設定ファイルをマウント
ports:
- "4317:4317" # gRPC
- "4318:4318" # HTTP
depends_on:
- django
5. otel-collector-config.yaml: データのルーティング設定
Collectorが「どこからデータを受け取り(`receivers`)」「どう処理して(`processors`)」「どこへ送るか(`exporters`)」を定義するファイル。
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318 # コンテナ内の全IPから受け取る
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
exporters:
# ローカルでログ確認したい時用
debug:
verbosity: detailed
# Grafana Cloudに送る場合
otlphttp/grafana_cloud:
endpoint: "${env:GRAFANA_CLOUD_OTLP_ENDPOINT}" # 環境変数から読む
auth:
authenticator: basicauth/grafana_cloud
extensions:
# Grafana Cloudの認証情報
basicauth/grafana_cloud:
client_auth:
username: "${env:GRAFANA_CLOUD_INSTANCE_ID}"
password: "${env:GRAFANA_CLOUD_API_KEY}"
service:
extensions: [basicauth/grafana_cloud]
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [debug, otlphttp/grafana_cloud]
logs:
receivers: [otlp]
processors: [batch]
exporters: [debug, otlphttp/grafana_cloud]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [debug, otlphttp/grafana_cloud]
結局、直接SDKとどっちがいいの?
まあ、面倒な部分もあるし、どっちがいいのかって話になる。個人的な整理としては、こんな感じ。
| 比較ポイント | OpenTelemetry (Collector経由) | 直接SDK (例: Datadog SDK) |
|---|---|---|
| ベンダーロックイン | ほぼ無い。Collectorの設定変えるだけ。楽。 | がっつり。乗り換えるならコードのあちこちを書き直し。考えたくない。 |
| 設定の複雑さ | 正直、最初はちょっと面倒。このCollectorの設定とか。一度作れば使い回せるけど。 | 楽。APIキー設定して数行書けばだいたい動く。手軽さはこっち。 |
| パフォーマンス | 間にCollector挟むから、ほんの少しオーバーヘッドあるかも。でも非同期だし体感はほぼ無い。 | エージェントが賢くやってくれる。これもオーバーヘッドは小さい。 |
| 柔軟性 | 最高。ログはこっち、トレースはあっち、とか自由にできる。 | そのベンダーの提供する機能の範囲内。まあ、だいたい十分だけど。 |
Celeryとか、本番で気をつけること
非同期タスクの[Celery]も計装できる。これは簡単。
6. celery_app.py: Celeryの計装
`celery_app.py`で、設定を読み込む前と `CeleryInstrumentor` を実行するだけ。
# celery_app.py
# ...
from contrib.otel_config import configure_opentelemetry
from opentelemetry.instrumentation.celery import CeleryInstrumentor
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'backend.settings.development')
# ★★★ この2行を追加 ★★★
configure_opentelemetry()
CeleryInstrumentor().instrument()
app = Celery('someapp')
# ...
7. 本番運用の注意点: サンプリング
最後に、これだけは。本番環境で全部のトレースやログを送ると、データ量もコストもすごいことになる。なので、サンプリングは必須。
例えば「エラーになったトレースだけ100%送って、正常なものは10%だけ送る」みたいな設定ができる。これは `TracerProvider` の設定でやる。詳しくは `opentelemetry-python` のドキュメントを見たほうがいい。
…と、まあこんな感じか。結局、最初の面倒さを乗り越えれば、後がすごく楽になるっていう、いつものやつ。でも一度このパイプラインを作っておくと、新しいプロジェクトでも使い回せるから、投資価値はあると思う。
みんな、可観測性の設定で一番ハマったのってどこ? Collectorの設定? それともコード側の計装? よかったら教えて。


