
落ちるサービスより、「勝手に復活するサービス」を育てたい
マイクロサービスって、ちゃんと動いてるときは気持ちいいんだけど、一個どこかでコケると一気に地獄になるやつじゃないですか。
だから最近、自分は Spring Boot でサービス作るとき、「機能が動くか」より前に「壊れても自力で立ち直れるか」を先に考えるようになってて、そのときにけっこうしっくりきた組み合わせが、Resilience4j のサーキットブレーカー + Chaos Monkey でのカオスエンジニアリングなんですよね。
ざっくり言うと、「外部APIとかが変な動きしても、サービス全体を巻き込まずに済ませる仕掛けを入れておく」「わざと壊しておいて、本当に耐えられるかを先に確認しておく」っていう話です。
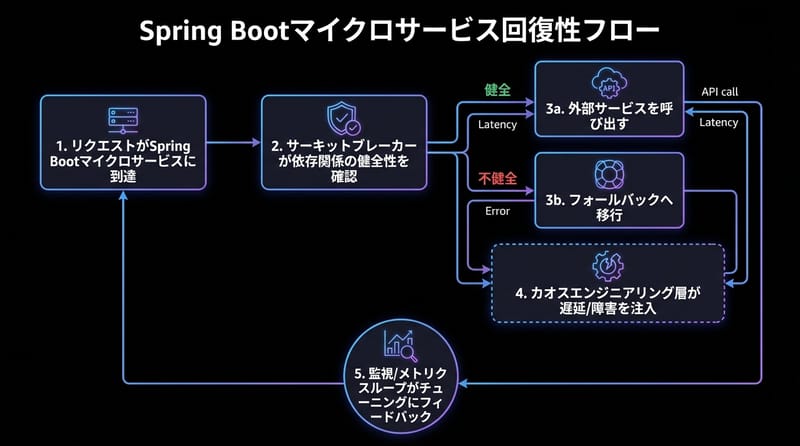
結論だけ先に言うと:マイクロサービスやってて「なんか最近よく落ちるな」と思ってるなら、ログを読む前に、サーキットブレーカーとカオスエンジニアリングを一回ちゃんと触っておくと、後でだいぶ楽になります。
なんでそこまで「レジリエンス」がうるさいのか
分散システムのめんどくささ:マイクロサービスって、サービスを小さく分けてデプロイしやすくして、チームごとに独立させて…みたいなきれいな話がよく出てくるけど、実際やると「依存サービスが増えただけ」とも言えるんですよね。
たとえば:
- 外部の決済 API がちょっと重くなる
- 在庫システムの DB が一瞬スパイクする
- 通知サービスのキューが詰まり始める
これのどれか一つが遅くなっただけで、フロントのレスポンスが一気に悪くなったり、タイムアウト連鎖したりして、「どこが悪いのかよく分からないけど全体的に遅い」状態になるやつ。
「たまたま大丈夫」は信用しない:台湾のプロジェクトでも、日本の SI 案件でも、最初のリリースのときって、負荷も少ないし外部 API もまだ優しいから「案外いけるじゃん」とか思うんですよ。
でもセール期間とか、momo や楽天のキャンペーンと重なったり、ちょっとだけトラフィックが増えた瞬間に、今まで気づいてなかった依存関係の弱さが一気に出てくる。
「ちゃんと作ったから大丈夫」じゃなくて、「壊れる前提で安全装置を入れてあるか」がマイクロサービスではだいたい勝ち筋。
その安全装置として分かりやすいのが、サーキットブレーカーとカオスエンジニアリングです。
サーキットブレーカーって、結局なにしてるやつ?
イメージ:家のブレーカーとほぼ同じで、「危なそうだから一旦スイッチ切っとくね」ができる仕組みです。
たとえば、Spring Boot のサービスから外部の決済 API を叩いているとして:
- 普段は普通にリクエストを投げる
- 失敗が一定割合を超えたら、「この API 今やばそうだな」と判断してスイッチを切る
- スイッチが切れている間は、そもそも外部 API を呼びに行かずに、フォールバック処理に流す
- しばらくしてから、ちょっとだけ試しにまた呼んでみて、大丈夫そうならスイッチを戻す
これをライブラリでやってくれるのが Resilience4j です。
Resilience4j を選ぶ理由:昔からある Hystrix とかも名前はよく出てくるけど、最近だと Java 17 とか Spring Boot 3 とか、環境が新しくなってきてるので、軽量でモジュール分割もされている Resilience4j の方が使いやすいって話をよく聞きます。
しかも Spring Boot Actuator と組み合わせると、サーキットブレーカーの状態や失敗率をメトリクスとして拾えるので、Grafana でダッシュボード作るのも楽。
コードの雰囲気:よくあるのは、決済サービスにこんな感じでアノテーションを貼るパターン。
@Service
public class PaymentService {
@CircuitBreaker(name = "paymentGateway", fallbackMethod = "paymentFallback")
public PaymentResponse processPayment(PaymentRequest request) {
// 外部の決済ゲートウェイ呼び出し
return paymentGatewayClient.process(request);
}
public PaymentResponse paymentFallback(PaymentRequest request, Throwable t) {
// リトライ用キューに積んでおく
queuePaymentForRetry(request);
return new PaymentResponse("Payment queued for retry");
}
}実際のプロジェクトだと、ここにタイムアウトやリトライ、レートリミットも一緒に絡めることが多いです。
具体的にどこにサーキットブレーカーを仕込むか
典型的な EC の注文マイクロサービスを想像すると、ざっくりこんな依存がありますよね:
- 決済ゲートウェイ
- 在庫システム
- メール / Push 通知サービス
全部に一律でサーキットブレーカーを入れる…というより、「落ちたときの痛さ」で優先度をつける方がやりやすいです。
決済ゲートウェイ:ここが一番クリティカル。失敗が続くなら、いったんキューに積んで「支払い処理中」として扱う、みたいなフォールバックが現実的。
在庫システム:在庫チェックに失敗したら、保守的に「在庫なし」と判断するか、一時的に新規注文を制限するか。B2B か B2C かでも戦略変わります。
通知サービス:ここは最悪後からまとめて送ればいいので、「通知だけキューに積んで、レスポンスは先に返す」というフォールバックが多いです。
つまり、サーキットブレーカーは「どこで諦めて、どうやって後処理に回すか」を決めるスイッチなんですよね。
でも、サーキットブレーカー「入れただけ」だと案外危ない
設定ファイルにそれっぽく threshold 書いて、アノテーション貼って、「はい完了!」ってやりがちなんですけど、ここからが本番で。
実運用だと、こんなパターンが普通に出てきます:
- 失敗率のしきい値が厳しすぎて、ちょっとしたネットワークの揺れでブレーカーが開きまくる
- 逆に緩すぎて、ブレーカーが開く前にスレッドプールが溶ける
- フォールバックの中で、また別の重い処理をやってしまって、意味がなくなる
ここで必要になってくるのがカオスエンジニアリングです。
カオスエンジニアリングって、Netflix だけの話じゃない
カオスエンジニアリングって聞くと、「Netflix みたいな巨大サービスがやるやつでしょ?」って空気がまだちょっとあるんですけど、小さめの Spring Boot マイクロサービスでも、むしろやった方がコスパいいなと思ってて。
Spring 系だとChaos Monkey for Spring Bootがそのまま使えるので、「ちょっと試しに壊してみる」がかなり気軽にできます。
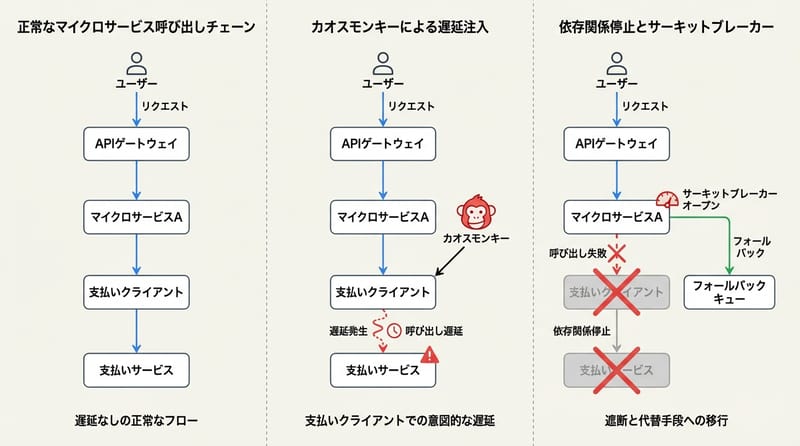
Chaos Monkey でよくやる遊び:
- 支払いクライアントにランダムな遅延を入れる(ネットワークぐずりの再現)
- 特定の Bean をランダムに kill して、例外を投げさせる
- 一定割合で強制的に失敗させる
これを、JMeter や k6 みたいなツールで負荷をかけながら回すと、サーキットブレーカーの設定が現実に合っているかどうかがだいたい見えてきます。
実際にカオスを入れてみると、どこがバレるのか
1. レイテンシーに弱すぎ問題:Chaos Monkey で 1〜3 秒くらいのランダム遅延を入れると、「タイムアウト設定が妙に長くて、スレッドが溜まりまくる」「逆に短すぎて、すぐに失敗扱いになってしまう」とかがすぐ見つかります。
ここで Spring Boot Actuator のメトリクス(サーキットブレーカーの状態や、外部呼び出しの成功/失敗率)を Prometheus 経由で拾って、Grafana で時系列を見ると、「どのレイテンシーでどんな挙動になってるか」が視覚的に分かりやすいです。
2. リトライストーム:外部 API が落ちているときに、リトライロジックが雑だと、「落ちている先に向かって、全サービスが全力でリトライを撃ち続ける」という地獄モードに入りがちです。
カオスを入れてみると:
- サーキットブレーカーが開くまでの間に、どれくらい無駄なリトライが飛んでいるか
- フォールバック側のキューや DB に、どれくらいの速度でタスクが溜まっていくか
このあたりの挙動がかなりはっきりします。
3. 想定してなかったフォールバックのバグ:「とりあえずキューに積んでおこう」とか「一旦保留にして後で処理」とか、フォールバック側の実装って、つい雑に書きがちなんですよね。
Chaos Monkey で依存先を完全に落としてみると、
- フォールバックで NPE が出て落ちる
- エラー文言がユーザーにそのまま見えてしまう
- 想定外の例外型が返ってきて、ハンドリングできていない
みたいなところがきれいにあぶり出されます。
レジリエンス設計で見ておきたい「表じゃない指標」
マイクロサービスの話をするときって、どうしても「平均レスポンスタイム」「エラー率」みたいな表面的な数字に寄りがちなんですけど、レジリエンスを見るなら、もう少し違うメトリクスが効いてきます。
サーキットブレーカーの状態遷移:「Closed / Open / Half-Open」がどれくらいの頻度で切り替わっているか。
たとえば:
- 一日に何回 Open になっているか
- Half-Open に戻したとき、どれくらいの割合で成功しているか
- 特定の時間帯だけ異常に Open が多くなっていないか
フォールバック率:全体のリクエストのうち、何%がフォールバック経由になっているか。
これが高すぎると、「一応サービスは生きてるけど、裏側はずっと火事」みたいな状態になっている可能性があります。
リトライキューの滞留時間:フォールバックでキューに積んだタスクが、平均どれくらいで処理されているか。
ここが長くなりすぎると、ユーザー体験としては「いつまでも処理中」のままになるので、SLA 的な観点でも危険ゾーンに入ります。
この辺を Spring Boot Actuator + Prometheus + Grafana みたいな王道セットで可視化しておくと、カオスエンジニアリングの結果も分析しやすいです。

Resilience4j × Chaos Monkey をざっくり比較してみる
役割の違いを、一回テーブルで並べた方がイメージしやすいかもしれません。
| 項目 | Resilience4j(サーキットブレーカー) | Chaos Monkey for Spring Boot |
|---|---|---|
| ざっくり役割 | 壊れたときの「安全装置」 | わざと壊して「弱点をあぶり出す」 |
| 使うタイミング | 本番・ステージング問わず常時 | 検証環境 or 本番でも慎重に一部だけ |
| メイン対象 | 外部 API 呼び出し、DB、メッセージキュー | Spring Bean、メソッドレベル、レイテンシー |
| 得られるもの | 連鎖障害のブロック、フォールバック経路 | 設計の穴、しきい値設定のまずさ、バグ |
| 開発チームへの効果 | 「とりあえず落とさない」安心感 | 「どこが本当に弱いか」の共通認識 |
じゃあ、自分のプロジェクトでどう始める?
一気に全部やろうとするとだいたい詰むので、個人的にはこんな順番が楽かなと思ってます。
1. 一番怖い依存先だけにサーキットブレーカーを入れる
まずは決済ゲートウェイとか、外部 SaaS(送信制限が厳しいメールサービスなど)みたいな、「止まるとビジネスインパクトが大きいけど、自分ではコントロールしづらい」依存先だけに絞る。
2. フォールバックの UX を決める
技術的な話より前に、「ユーザーにどう見せるか」を決めておくと、フォールバックの実装がブレにくいです。
- 決済なら「処理中」として保留にするのか
- 在庫なら「一時的に購入不可」にするのか
- 通知なら「後でまとめて送る」だけでいいのか
3. Chaos Monkey をステージングにだけ入れて、軽く壊してみる
いきなり本番でやるのはさすがに怖いので、まずはステージングで:
- レイテンシーを入れてみる
- 特定の Bean を kill してみる
くらいから始めると、サーキットブレーカーの設定の「雑さ」がすぐ見えてきます。
4. メトリクスを一枚のダッシュボードにまとめる
Prometheus + Grafana でも、Datadog でもいいので、
- 外部呼び出しの成功率・失敗率
- サーキットブレーカーの状態
- フォールバック率
あたりを一画面で見えるようにしておくと、カオスを入れたときの挙動が一気に理解しやすくなります。
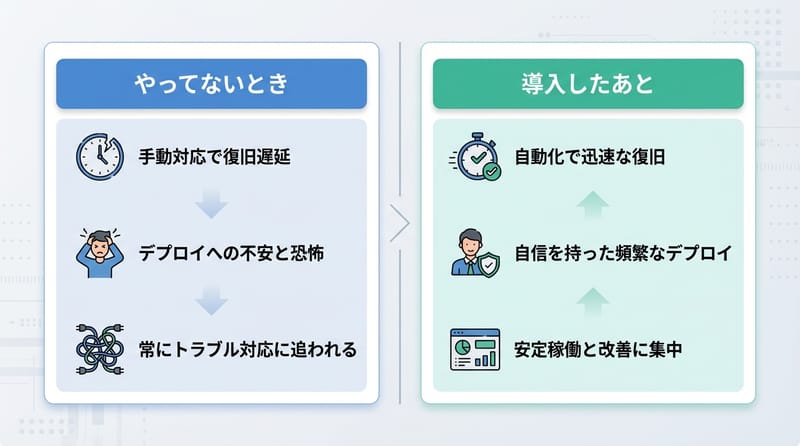
正直なところ、自分が一番楽になったポイント
インシデントのときの会話が変わる:前までは障害が起きると、
- 「どこが悪いのかよく分からない」
- 「とりあえず全部のログ見よう」
みたいな空気になりがちだったのが、サーキットブレーカーとカオスエンジニアリングを一周回した後だと、
- 「今どのブレーカーが Open になってる?」
- 「フォールバック率が急に上がったのはどこ?」
みたいな、少しだけ構造化された会話になるんですよね。
「落ちないコード」から「壊れても戻ってくるシステム」へ:コード単体をどれだけきれいに書いても、外の世界は好き勝手に壊れるので、結局は「壊れ方」と「戻り方」を設計しておいた方が精神衛生がいい。
サーキットブレーカーとカオスエンジニアリングは、そのためのわかりやすい入口、みたいな感じがしています。
テストで一度も壊してないシステムを、本番に出すのはけっこうギャンブル寄りの行為。
最後に、どこから一歩目を踏み出すか
もし今、Spring Boot でマイクロサービスをやっていて、
- 外部 API の調子にいつも振り回されている
- 障害のたびに、どこから見ればいいか迷う
みたいな状態なら、まずは一番怖い依存先にだけ Resilience4j を入れてみて、その上で Chaos Monkey をステージングに仕込んで軽く遊んでみる、くらいからで十分です。
今すぐ全部完璧にやる必要はないので、今日は「一番クリティカルな外部サービスにだけサーキットブレーカーをつけてみる」ところまで、軽く手を動かしてみてください。
そこから先で、「あ、ここも壊れうるな」と思った場所が増えてきたら、そのときまた一緒に悩めばいいと思います。


