
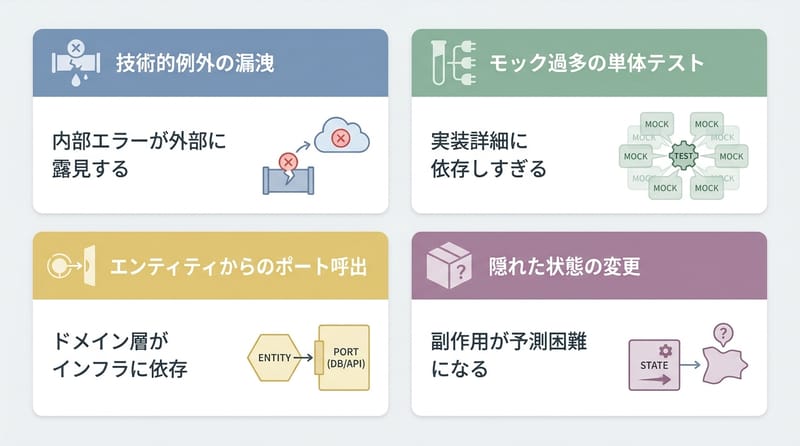
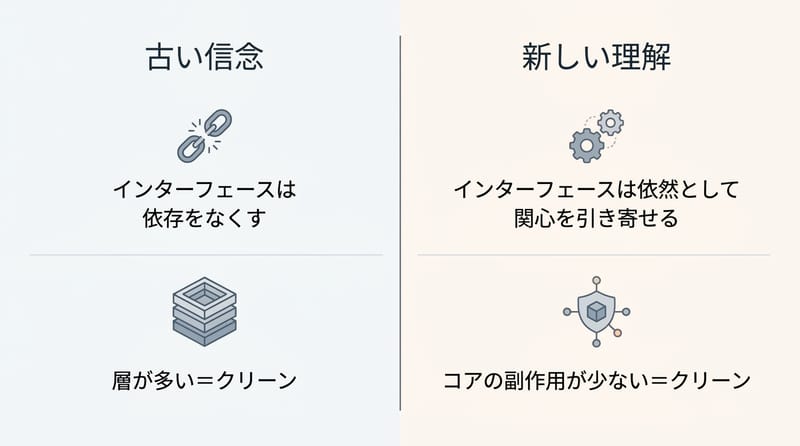
ヘキサゴナルアーキテクチャやクリーンアーキテクチャにDDDのリッチドメインを重ねると、ドメインが例外処理と依存で汚れ、テストにモックが増える。
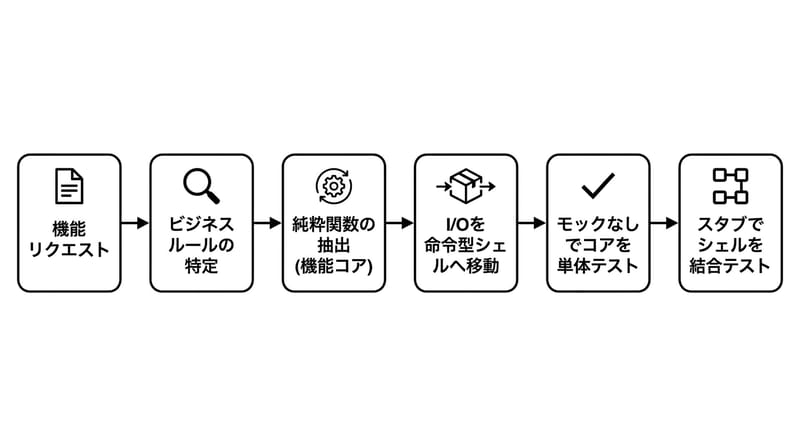
機能的中核と命令的シェルは、純粋関数に業務ルールを閉じ込め、I/Oと副作用を外縁へ追い出して保守性とテスト容易性を上げる。(出典:Gary Bernhardt「Functional Core, Imperative Shell」)
- ドメインが「リポジトリ例外」を握ってないか
- ユニットテストがモック祭りになってないか
- データが片道で流れてるか(戻り呼び出し地獄がないか)
- 副作用はシェルに集約されてるか(ログ、HTTP、DB)
でさ。これ、分かってるつもりでも、いつの間にか逆走するんだよね。
結局どっちが楽なのかって話
Functional Core/Imperative Shellは、業務ロジックを純粋関数に集約し、HTTP・DB・ログなどの副作用をシェルへ隔離する設計パターンだ。
先に結論:「レイヤーを綺麗に積む」より、「副作用を外へ捨てる」ほうが、長期的に胃が痛くならない。ほんとに。
昔の自分、HA/CAを採用して、DDDもやって、エンティティはリッチで…ってやったことある。最初は気持ちいいのよ。境界がある感じがして。
でも数ヶ月すると、ドメインの中に「技術の匂い」が混じる。
匂い、っていうか、普通に混入。混ざる。
たとえば、ドメインが UserRepository(永続化の窓口インターフェース)を呼ぶようになって、DB接続失敗とかタイムアウトとか、そういう「業務じゃない」エラーの都合を、結局ドメイン側が知る羽目になる。これが原文の言う functional dependencies の地獄。
HAとCAとDDDが悪いというより、混ぜ方が事故る
Hexagonal Architectureはポートとアダプタで外部システムを隔離し、Clean Architectureは同心円のレイヤーで依存方向を内側へ固定する。
用語の釘打ち:ポート(抽象インターフェース)とアダプタ(具体実装)って、要は「差し替え口」と「変換器」ね。で、DDDのリッチドメインモデルはエンティティに振る舞いを持たせるやつ。
ここまでは、教科書的には美しい。うん、分かる。
でも、実装って教科書じゃないじゃん。雨の日の駅の階段みたいに滑る。
混乱の入口:「インターフェースだから依存してない」って錯覚。依存してるんだよ。形が柔らかいだけで。
エンティティが ExportUserPort とか呼び始めた瞬間、外側の都合が内側の設計を押し曲げる。しかも静かに。
静かに壊れるのが一番イヤ。
あと、例外。例外処理って、だいたいインフラ寄りじゃん。DB落ちた、ネット落ちた、ファイル書けない。業務ルールじゃない。なのに、レイヤーを守るためにドメインが「例外の形」を意識しだす。終わりの始まり。
純粋関数の機能的中核が強いのは、モックを殺せるから
純粋関数は入力だけに依存し、副作用なしで出力を返すので、ユニットテストはデータを渡して結果を比べるだけになる。
純粋関数:外部I/Oをしない、共有状態をいじらない、同じ入力なら同じ出力。これだけ。妙に宗教っぽく聞こえるけど、現場だと単純に助かる。
原文の例のやつね。
calculateMembershipLevel(userData) -> newMembershipLevelこれ、テストがマジで軽い。userDataを投げて、期待値を見る。それで終わり。
モック?いらない。スタブ?だいたい要らない。
あの「リポジトリのモックがRepositoryMockFactoryを呼んで…」みたいな、呪いの儀式が消える。
消えると、脳の空きが増える。これ、体感ある。
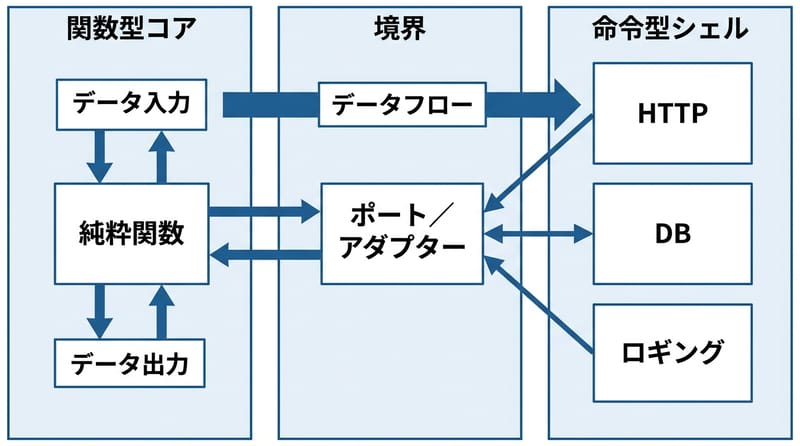
片道データフロー:シェルが集める→コアが変換する→シェルが書き戻す。往復ビンタみたいな呼び出しをしない。これが地味に効く。
HTTPサーバの例もそのまま使える。シェルがリクエストを受け取って、ヘッダ読んで、bodyパースして、必要なデータ構造にして、純粋関数(たとえば calculateDiscount)に渡す。結果をJSONにして返す。はい終了。
途中で「ドメインがHTTPのステータスコードを知ってる」みたいな変なことが起きない。
起きないのが正義。地味だけど。
実装で詰まるのはエラー処理、そこはシェルが持て
DB到達不能やネットワーク失敗は業務ルールではないため、Functional Coreでは扱わず、Imperative Shellがエラーを回収して制御する。
ここでよく揉める:「でも業務的にエラーに反応するじゃん?」って話。分かる。分かるけど、分け方を変える。
たとえばDBが落ちたら「割引計算はできません」って返す。これは業務の顔をしてるけど、原因はインフラ。だからシェルが「落ちた」ことを受けて、業務に渡すデータを Option型(値がある/ないを表すデータ表現)とか Result型(成功/失敗をデータとして返す表現)にして、コアに渡す。
コアは「失敗が来たらこういう業務上の返しをする」ってだけやる。原因分析とかリトライとかはシェル。
この分離、慣れるまで気持ち悪い。でも慣れると戻れない。
戻ると、またモックが増える。増えると、テストが遅くなる。遅いと、人はテストを書かなくなる。
人間はそういう生き物。悲しいけど。
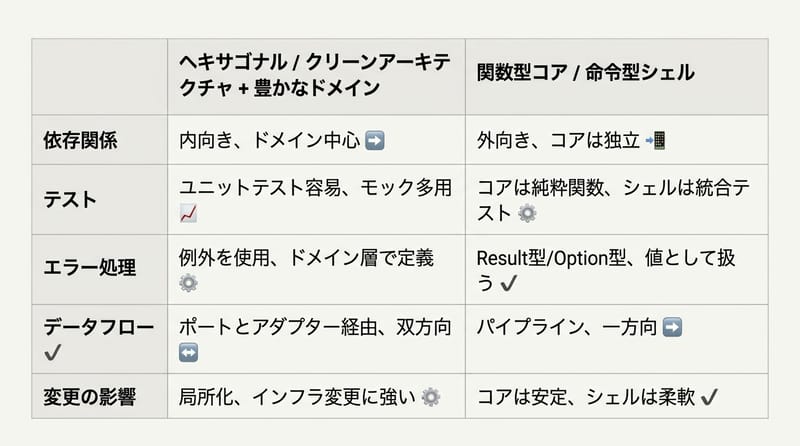
| 観点 | 良いところ | しんどいところ |
|---|---|---|
| HA/CA + DDD リッチドメイン | 境界の言語が揃うと、図としては綺麗。設計議論もしやすい。 | 例外やI/O都合が漏れて、ドメインが技術っぽくなる。テストがモック依存になりがち。 |
| Functional Core / Imperative Shell | 純粋関数が小さくてテストが速い。変更点が「この関数」って指差せる。 | 最初の分割が難しい。境界の設計(データ構造、型、変換)が下手だとシェルが太る。 |
あ、これも言っとく。HA/CAを完全否定する必要はない。
原文もそこは現実的で、構造の青写真として残していいって言ってる。ポート/アダプタは境界で使う。ただしドメインは純粋関数に寄せる。これが落としどころ。
スクショ用の自分チェックリスト
規則:下の12個のうち、YESが7個超えたら「コアを純粋化する余地」が普通にある。自分の経験上、ここで放置すると後で泣く。
- ドメイン層のテストが、モックの設定で半分埋まる
- エンティティがリポジトリやポートを呼んでいる
- 「DBが落ちた時の例外」をドメインが知っている
- ログ出力がドメインの中にいる(なぜ…)
- ユースケースの流れが双方向に飛び回る
- テストが遅くて、実行頻度が落ちている
- 変更の影響範囲が読めず、毎回ビクビクする
- データの変換があちこちで起きて、同じことを3回やってる
- 例外が「とりあえず握りつぶす」方向に育ってきた
- リッチモデルが継承やオーバーライドで巨大化している
- 境界(HTTP/DB/外部API)と業務ロジックの線が曖昧
- 「この設計、誰のため?」って会話が増えた
最後に小さい挑戦、やってみて
ド派手なリファクタは要らない。というか、だいたい死ぬ。
挑戦:今ある機能から1本だけ選んで、ドメインの中の「判断」を純粋関数に抜き出して、テストをモックなしで書く。1時間で終わる範囲で。
終わったら、テストコードの行数じゃなくて、頭の疲れが減ったか見てほしい。そこが指標。
で、減ってたら…次をもう1本。増えてたら、境界のデータ設計が雑だった可能性が高い。そういう時は、だいたいシェルが変換地獄になってる。
現実って残酷。だけど、残酷さは早めに見たほうがマシなんだよね。

