
這可能是你聽過最大的誤解:MCP 不是「讓 AI 直接打你 API」那麼粗暴;MCP 是 Anthropic 的 Model Context Protocol,用 discover と execute 把 Nanoservice-ts の Nodes と Workflows を安全に“ツール化”して Claude から呼べる規格だ(來源:Anthropic MCP 仕様・Nanoservice-ts)。
- まず見る場所:
discoverで「使える道具の一覧」を返す - 次に起きる:
executeで「この道具をこの引数で実行」を受ける - 守るポイント:公開するツールを絞る+JSON Schema(入力の型と制約)で弾く
- 設計の癖:ビジネスロジックはそのまま、薄いアダプタだけ足す
- 地味に大事:監査ログと認可。ここサボると後で泣く
「AI とつなぐ」って聞くと、みんな最初は“魔改造”の匂いを想像するんだよね。既存のバックエンドが、急に会話っぽい何かに飲み込まれる感じ。違う。そこ、違うの。ほんとに。
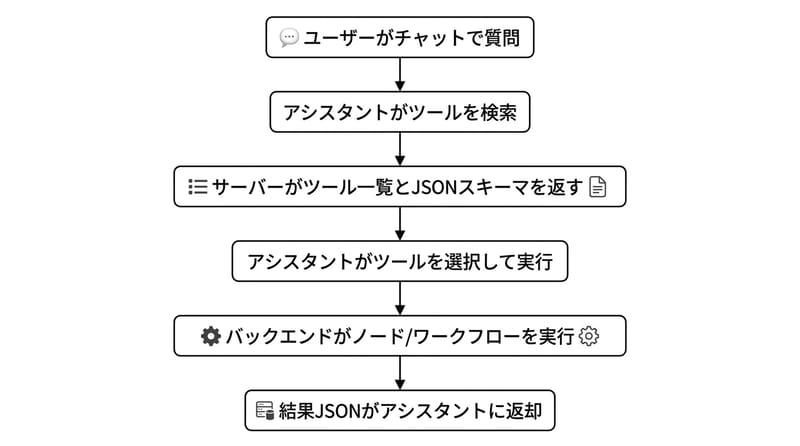
で、MCP はその混乱を避けるための“取り決め”。会話でお願いされた内容を、いきなり内部の関数に投げない。いったん「道具箱」を見せて(discover)、その後に「どれを、どういう引数で使うか」を決めて(execute)、結果を返す。
…って言うと簡単そうだけど、簡単に見えるところほど事故る。えぐい。
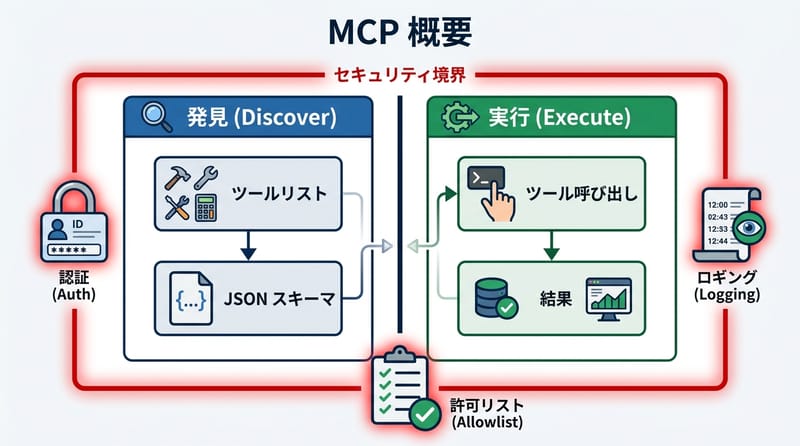
まず結論から言うと MCP は道具箱の見せ方と呼び方の約束
MCP は discover でツール定義(name・description・schema)を返し、execute でツール名と parameters を受け取り、実行結果を構造化して返すプロトコルだ(來源:Anthropic MCP 仕様)。
用語の置き場:ここ、混ぜるとチームが揉めるから先に固定しとくね。
- Model Context Protocol:AI が「使えるツール」と「呼び出し方」を理解するための共通フォーマット
- JSON Schema(入力の型と制約):parameters の必須・形式・範囲を機械的に検証する定義
- Stateless Trigger(状態を持たない入口):HTTP みたいにリクエスト単位で処理して終わる入口。セッション依存にしない
この discover / execute の分離が、地味に効く。なぜかっていうと、AI 側は「勝手に何でも叩ける」状態じゃないから。道具箱に入ってないものは、存在しないのと同じ扱いになる。
それと、返す結果も “文字列でそれっぽく” じゃなくて、JSON で返す。ここが「会話→行動」を壊さないコツ。
MCP のキモは「AI に自由を渡す」じゃなくて、「使っていい範囲を形式で囲う」こと。
discover はツール一覧のカタログで execute はレジの会計
discover は name・description・schema を列挙して返し、execute は name と parameters を受けてバックエンド処理を走らせる二段構えだ。
たとえば、原文の例だとこういうやつ。
[
{
"name": "create_user_account",
"description": "Creates a new user given an email and optional name.",
"schema": { "type": "object", "properties": { "email": { "type": "string" } } }
},
{
"name": "send_welcome_email",
"description": "Sends a welcome email to a user.",
"schema": { "type": "object", "properties": { "userId": { "type": "string" } } }
}
]で、呼び出し側(Claude みたいなアシスタント)が「じゃあこれ使う」って決めたら execute。
{
"name": "create_user_account",
"parameters": {
"email": "john@example.com"
}
}返すのはこう。うん、こういうのがいい。余計な飾りなし。
{
"userId": "abc123",
"status": "success"
}ちょっと怖い話:ここで “description を雑に書く” と、AI がツールの用途を誤解して変な順番で叩くことがある。説明文、後回しにしがちだけど、割と痛い目みる。
あ、あと。schema ね。ここを空にしたくなる瞬間あるけど、やめときな…。夜に呼び出しログ見て固まるやつ。
Nanoservice-ts が刺さるのは Node と Workflow がそのまま道具になるから
Nanoservice-ts は Nodes(単機能でテストしやすい関数)と Workflows(Nodes の合成)を持つため、MCP の「小さく定義されたツール」にそのまま対応する(來源:Nanoservice-ts ドキュメント)。
ここ、私はけっこう好き。理由が生々しいから。
普通のバックエンドって、API の都合で処理が太るでしょ。エンドポイントに色々詰め込みがち。で、後から AI 連携したいってなると「何をツールとして切り出す?」で揉める。揉めるのよ。
でも Nanoservice-ts は最初から “細い部品” が前提。Node は「これだけやる」、Workflow は「順番に組む」。MCP が欲しがる粒度に近い。
トリガーの話:Stateless Triggers が入口になれる、ってやつ。HTTP でもキューでも、入口が「状態を持たない」設計だと、会話のたびに変な状態が残らない。ここ、地味だけど後々ラク。
あ、そうだ。TypeScript の型。型があると schema を起こすのが…まあ、少しは、気がラク。全部自動は期待しすぎだけどね。
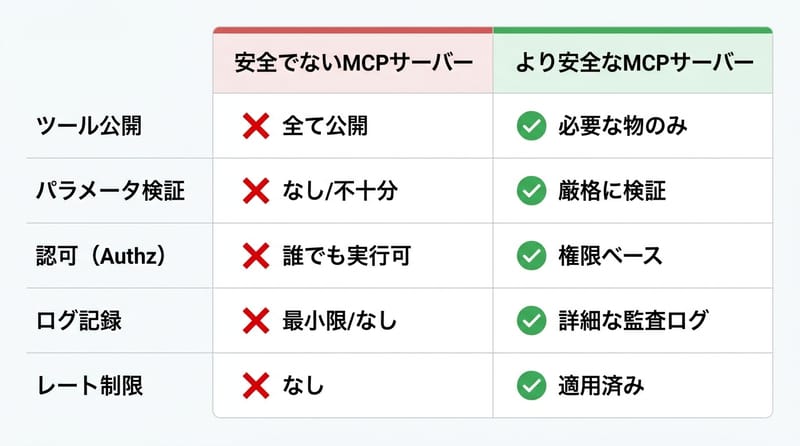
安全にやるなら allowlist と JSON Schema と認可をセットで持て
MCP サーバーは allowlist(公開ツールの許可リスト)と JSON Schema 検証と認可を同時に実装し、実行ログを監査可能な形で残すべきだ。
規則:「動く」より先に「止められる」を作る。これ、順番。
- allowlist:公開するツール名を固定。内部用の危ない処理は最初から出さない
- JSON Schema 検証:必須項目抜け、文字列の形式、想定外のフィールドを弾く
- 認可:誰がどのツールを実行できるか。ユーザー権限・ロールで切る
- レート制限:連打でメール送信とか、普通に起きる。止める壁を置く
- 監査ログ:誰が・いつ・何を・どの引数で・結果はどうだったか
ここで日本ローカルの話も混ぜるね。SaaS で個人情報(メールアドレスとか)を触るなら、個人情報保護法の観点で「アクセス制御」と「ログ」って、後から説明を求められる側に回りがち。つまり、最初から用意しておくと眠れる。(來源:個人情報保護委員会 公開資料)
あと、社内の監査とか ISMS(ISO/IEC 27001)を通す会社だと、ツール実行の証跡を聞かれる。聞かれるの。ほんとに。
AI 連携は「便利」より先に「誰が責任持つの?」が来る。逃げ場ない。
時間とお金のマトリクス どこに投資すると損しにくいか
MCP 導入は「アダプタ実装」「スキーマ整備」「認可とログ」「運用監視」に分かれ、時間と費用の配分を誤ると手戻りが発生しやすい。
ここ、計算しよ。ふわっと「やってみよう」って言い出す人、だいたい後で消えるから。残るのは実装した人。あなた。私。うん…。
| 投資ポイント | 時間コスト | 金銭コスト | サボった時に起きがち | 先にやる目安 |
|---|---|---|---|---|
| ツールの棚卸しと命名 | 0.5〜2日 | ほぼ0円 | 似たツール名が増えて AI が誤爆、運用がカオス | 最初 |
| JSON Schema 整備 | 1〜5日 | ほぼ0円 | 入力が崩れて例外祭り、ログが赤く染まる | 最初 |
| allowlist+認可 | 1〜3日 | 0〜(既存 IAM 次第) | 権限の穴から内部操作が走る。後で説明地獄 | 最初 |
| 監査ログ設計 | 1〜4日 | 0〜(ログ基盤次第) | 原因追跡できず、障害対応が長引く | 最初〜早め |
| アダプタ実装(Node/Workflow を MCP 化) | 2〜10日 | 0円 | ここだけ先にやると“動くけど危ない”が完成 | 安全設計の後 |
| 監視とレート制限 | 0.5〜3日 | 0〜(監視ツール次第) | 連打・暴走に気づけない、コストも跳ねる | リリース前 |
私のおすすめの順番:「棚卸し→Schema→認可→ログ→アダプタ」。逆にすると、後で全部やり直す率が上がる。ほんと。静かに死ぬ。
あ、金銭コストのところが “0〜” なの、現実の匂いするでしょ。既存の認証基盤、ログ基盤、監視がある会社は強い。ない会社は、そこから。
手を動かすなら まずは入口とレジストリとアダプタを作る
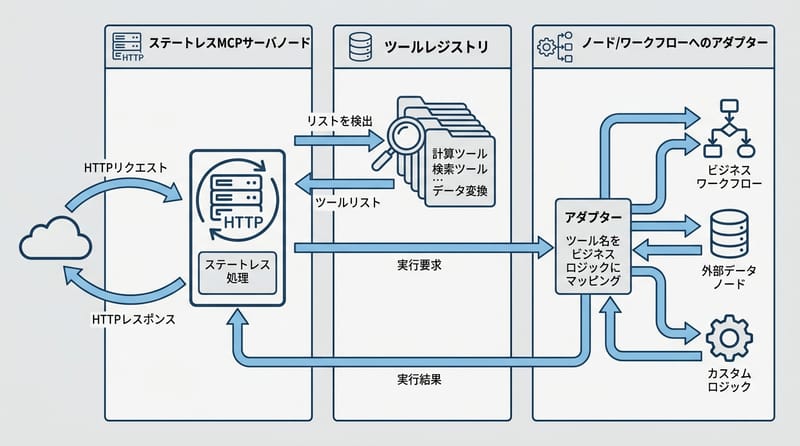
実装は Stateless MCP Server Node を入口にし、Tool Registry で自動 discover を実現し、Node と Workflow をアダプタで MCP 準拠ツールに包むのが基本形だ(來源:Nanoservice-ts・Anthropic MCP 仕様)。
原文の「Part 2 でやること」を、会話っぽく並べ替えるとこう。
- 入口:Stateless MCP Server Node(HTTP ハンドラみたいなやつ)
- 台帳:Tool Registry(discover の返却をここから作る)
- 包み紙:Adapters(既存 Node/Workflow を MCP の tool 形に合わせる)
- 往復:Claude から呼んで結果が返るところまで通す
このへんで急に「全部自動で discovery できる?」って聞かれるんだけど、できる範囲はある。Node と Workflow が明確なら、列挙はしやすい。
ただ、description と schema は、人間の責任が残る。残るよ。AI に任せると、それっぽいけど危ないのが出てくる。ここは、あなたの目。
具体ツール名:JSON Schema を扱うなら Ajv みたいなバリデータを使うチームが多い(來源:Ajv 公開情報,建議查證)。ログは OpenTelemetry を噛ませておくと、後から追跡しやすい(來源:CNCF OpenTelemetry)。
うん、今 OpenTelemetry って言った瞬間、眠くなった人いるでしょ😶 でも障害の夜に助けてくれるのも、だいたいそういう地味なやつ。
FAQ ここだけは先に潰しておきたい
規則:FAQ の答えは短く断言で書く。ここは迷わせない。
Q:MCP を入れると既存 API を作り直す必要ある?
MCP は既存の Node と Workflow を薄いアダプタで包む方式なので、ビジネスロジックを作り直さずにツール公開へ寄せられる(來源:Nanoservice-ts ドキュメント)。
Q:discover で全部の機能を公開していい?
discover は allowlist で公開範囲を固定し、内部運用や危険操作の Node は一覧に出さないのが前提だ。
Q:JSON Schema は何のために入れる?
JSON Schema は parameters の必須・型・制約を機械検証して不正入力を遮断し、ツール実行の例外と誤動作を減らすために使う(來源:JSON Schema 仕様)。
Q:会話からユーザー作成やメール送信って、怖くない?
会話経由の実行は認可・レート制限・監査ログを揃えれば統制でき、誰が何を実行したか追える状態にできる。
Q:Nanoservice-ts じゃないとダメ?
MCP は実装言語に依存しないが、Nanoservice-ts は Node と Workflow の粒度が MCP ツールに合わせやすい設計だ(來源:Anthropic MCP 仕様・Nanoservice-ts)。
最後に一個だけ:「言語が UI になる」って、聞こえは派手。でも現場は、地味な配線の勝負。discover の中身、schema の硬さ、ログの粒度。そういうの。
で、聞きたい。あなたの現場だと、いま Claude に「ユーザー作成」「メール送信」「注文処理」みたいな操作、どこまで許せそう?それとも、まずは “読み取り専用のレポート生成” から始める感じ?

