
これ、多分いちばんデカい誤解なんだけど。
「スキーマって最初に決めたら終わり」って思ってると、データ基盤はだいたい静かに死にます。🙂
スキーマ進化(Schema Evolution)は、APIやストリーミングで変わり続けるデータの構造変更を、パイプラインを壊さず吸収する設計と運用のことです。Delta LakeやApache Icebergは、列追加や型変更を履歴管理しながら扱えます。
- まず見る:変更は「列追加」か「型変更」か「名前変更」か
- 次に守る:後方互換(古いデータでも動く)
- 事故りやすい:複数ソース混在、ストリーミングの途中で型が揺れる
- 効く道具:Delta Lake / Apache Iceberg / AWS Glue / Great Expectations / DataHub / dbt
- 最後に:「ルール化+検証自動化」しないと運用で燃える
スキーマ進化って結局なに
スキーマ進化(Schema Evolution)は、データ構造の変更を受けても、取り込み・変換・分析の流れを止めずに動かし続ける仕組みです。
で、ここで「スキーマ」って何かというと、データの設計図。列名、型、必須か任意か、みたいなやつ。
昔のシステムって、スキーマがカチカチで、列が1個増えただけでジョブが落ちたりする。落ちたらまだマシで、落ちずに間違ったまま流れるのがいちばん怖い。うわ、ってなるやつ。
データレイク系、特にDelta Lakeとか、Snowflakeみたいな現代寄りの仕組みは、そこを「変わる前提」で作ろうとしてる。変わる。絶対変わる。人の要求ってそういうもん。😮💨
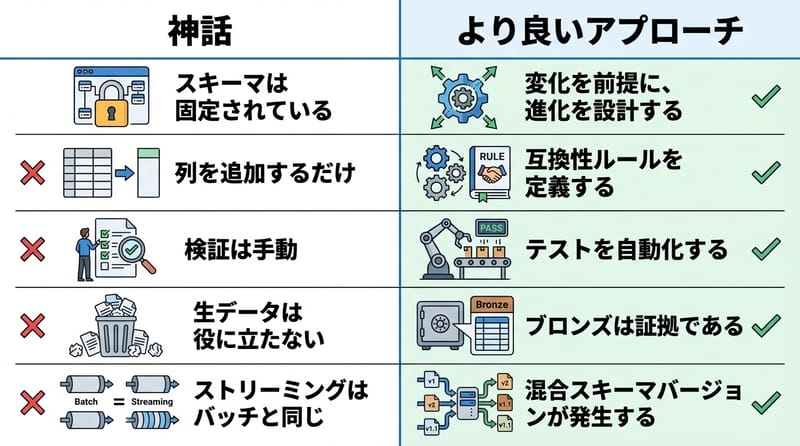
「スキーマは仕様書じゃなくて、生き物。放置すると暴れる。」
なんでスキーマ変更がそんなに厄介なの
スキーマ変更が厄介なのは、データの構造が変わると下流の前提が連鎖的に崩れるからです。
リアルタイムのAPI、IoT、アプリイベント。こいつら、昨日と言ってることが違う。
追加の列が来る。名前が変わる。型が変わる。必須になったり、逆に消えたり。
で、現場って「止められない」んだよね。止めた瞬間、数字が見えなくなる。経営会議で沈黙が発生する。怖い。🙂
進階っぽい指標の話:単に「ジョブ成功率」じゃなくて、私はSchema Drift Rate(一定期間に起きるスキーマ差分の頻度)と、Breaking Change Ratio(互換性を壊す変更の割合)を見たくなる。これ、運用の体感と一致しやすい。
あ、今ふと思い出したけど、データ品質の事故って「遅延」より「静かな誤り」が長引くのが致命傷。発見が遅れる。犯人が分からない。探偵モード突入。🕵️

つまずきポイントはだいたい4つ
スキーマ進化の難所は、後方互換・データ欠損・型不一致・アップグレードとダウングレードの4つに集約されます。
後方互換:新旧のスキーマが混ざっても、下流が動く状態を保つこと。
例えば列名変更。これ、地味にヤバい。古い列名で参照してるSQLが全部死ぬ。
列追加はまだ優しい。優しいけど「必須」になった瞬間、牙をむく。
データ欠損:複数ソースで進化タイミングがズレると、片方だけ列がある/ないが発生する。
例のCSV:customer_id, amount_spent, timestamp の3つで来てたのに、ある日 payment_method が増える。増えた瞬間、古いファイルが「列足りません」扱いになると、取り込みが落ちる。
落ちるならまだいい。落ちずに null が増殖して、あとから集計が変な顔するのが怖い。
型不一致:int が float や decimal になるやつ。
金額でこれやるの、めちゃ多い。最初は整数でいけたけど、税とか手数料とか、端数が出てくる。で、精度が欲しくなる。自然。
でも下流のテーブル定義が追いついてないと、キャスト失敗、丸め、最悪は桁落ち。
アップグレード vs ダウングレード:新しい列 discount_code を足した。でも古いレポートは、その列が存在しない前提で動いてた。
「過去の数字を同じ条件で再現したい」って要求、しれっと来る。だいたい夜に来る。🙂
対処の基本は5つの手筋
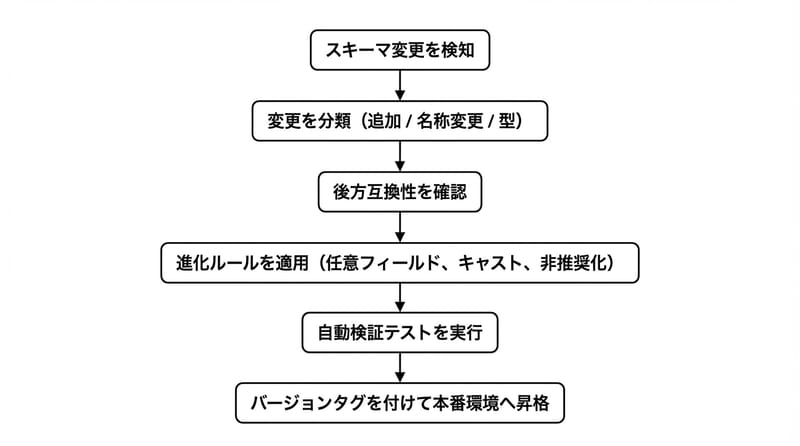
スキーマ進化を運用で回す基本は、スキーマのバージョニング、Schema-on-Read、進化ルール定義、検証自動化、変換レイヤー整備です。
1) スキーマをバージョン管理:スキーマをコードみたいに扱う。変更したら「v2」「v3」って履歴を残す。
Delta LakeやApache Icebergは、この「履歴と進化」の考え方と相性がいい。ここは素直に乗った方が楽。
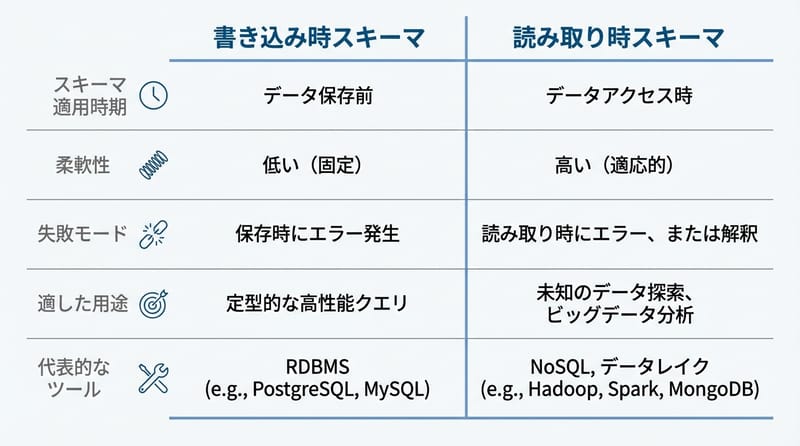
2) Schema-on-Read を使う:書き込み時に厳密固定するより、読み取り時にスキーマを当てる発想。
AWS Glue みたいにカタログやクローラで「今こんな感じ」を把握して、クエリ側で吸収する。万能じゃないけど、現実の泥を吸ってくれる。
3) 進化ルールを明文化:「列追加は最初は任意」「型変更はキャスト規則必須」「列廃止はdeprecatedで猶予」みたいに、決める。
決めないと、毎回その場のノリで処理して、半年後に誰も説明できない化け物になる。
4) 検証を自動化:Great ExpectationsやDataHubで、スキーマと品質チェックをテストに落とす。
「新しい列が増えたら通知」「型が変わったら失敗」「必須列がnullなら止める」みたいなやつ。地味。地味だけど効く。
5) 変換レイヤーを整える:dbt、Spark、Pandasで、欠損列を補う・リネームを吸収・型を揃える。
正直ここ、職人芸になりやすいから、ルールとテストで縛っておかないと、後で泣く。
ストリーミングだと何が起きるか
Kafkaのようなストリーミングでは、同じトピックに新旧スキーマが同時に流れ、スキーマ進化の問題が一気に表面化します。
ライドシェアっぽい例ね。ユーザー、トリップ、位置情報、決済。時間が経つと ride_status とか payment_method とか surge_multiplier とか増える。増える増える。
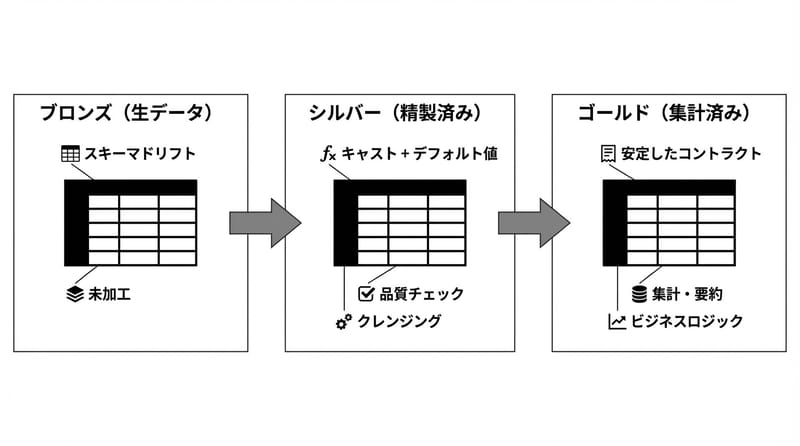
流れとしては、だいたいこんな感じ。
- Ingest:Kafkaでイベント収集
- Bronze:Delta Lakeに生で貯める(まず証拠保全)
- Silver:欠損補完、型合わせ、列追加の吸収
- Gold:集計して「安定した契約」を提供
- Serve:BIがクエリ、増分処理で追随
ここで探偵っぽい質問を投げるとさ。
「今流れてきたそのイベント、どのスキーマ版?」
このタグ付け(バージョンや互換ルール)が曖昧だと、調査が地獄。ログ掘って、夜が溶ける。🙂
分かってる人ほど決めてる運用ルール
スキーマ進化は「技術」だけでなく、変更をどう通すかという運用設計で勝負が決まります。
ここ、ちょい現実寄りにいくね。日本の現場だと、データが社内の複数部門に跨ってたり、ベンダー提供のCSVが混ざってたりする。
で、変更連絡が…来ない。来ても遅い。あるある。
通路の話:データ基盤の運用って、結局「どこで誰が見てるか」が大事で、社内ならJira/Backlogで変更申請を切るとか、Slackの専用チャンネルでスキーマ差分通知を流すとか、そういう地味な導線が効く。
ツールとしてはDataHubでメタデータ追えると、あとから「誰が何を変えた?」を辿りやすい。証拠が残る。大事。
「スキーマ変更は技術イベントじゃなくて、コミュニケーション事故として起きる。」
人によって最適解が違うやつ
スキーマ進化の設計は、チームの働き方とデータ利用者の性格で最適解が変わります。
規則:ここだけ「If This Then That」置いとく。刺さる人には刺さる。🙂
- 外食族みたいに「毎日状況が違う」チームなら:Schema-on-Read寄り+Bronzeに生保存、Silverで吸収。まず止めない。
- 夜班みたいに「障害対応が少人数」チームなら:Great Expectationsで検証を厚めにして、Breaking Changeは即アラート。寝不足は敵。
- 親子みたいに「利用者が多くて要求が増える」組織なら:スキーマのバージョニングとdeprecated期間を明文化。急に消すと炎上する。
- 銀髪…じゃなくてベテラン運用が強い組織なら:Iceberg/Deltaの履歴とデータ契約(Goldの安定スキーマ)を固めて、下流の安心を優先。
なんか例えが変? まあいいや。言いたいのは「全員に同じ正解」はないってこと。
最後に、ツールを1個だけ握るなら
スキーマ進化の最初の一手は、スキーマ差分の検知と検証を自動化し、変更を「見える化」することです。
もし「何から触れば…」って状態なら、私はまずGreat Expectationsを推す。理由は単純で、スキーマと品質をテストにできるから。
で、メタデータ追跡にDataHub。変換はdbt。ストレージはDelta LakeかIceberg。オーケー、って感じ。
あ、免責っぽいのも一応。
注意:ここで書いたのは一般的な設計の話で、要件(SLA、監査、個人情報の扱い)で最適解は変わります。現場の制約、ほんとに強いからね。
FAQ みんながそこで詰まる
規則:FAQの答えは短く、でも曖昧にしない。
Q. スキーマ進化って、結局は列追加を許すってこと?
スキーマ進化は列追加だけでなく、列名変更・型変更・必須化などの変更を、互換ルールと検証で安全に扱うことです。
Q. Schema-on-Read にすれば全部解決?
Schema-on-Readは柔軟性を上げますが、型の揺れや必須項目の欠損は残るので、検証自動化と変換レイヤーが必要です。
Q. ストリーミングで一番怖いのは?
ストリーミングは新旧スキーマが同時に流れるので、バージョン識別と後方互換が曖昧だと下流の集計が静かに壊れます。
Q. どのツールから入るのが無難?
Great Expectationsでスキーマ検証を自動化し、DataHubで変更履歴を追えるようにすると、最初の事故率が下がります。
で、結局さ。
スキーマ進化って「変化を許す」話じゃなくて、変化を管理する話なんだよね。ふわっと許すと燃える。
金句:変わるのはデータじゃなくて、変わる前提を持たない運用のほう。


