
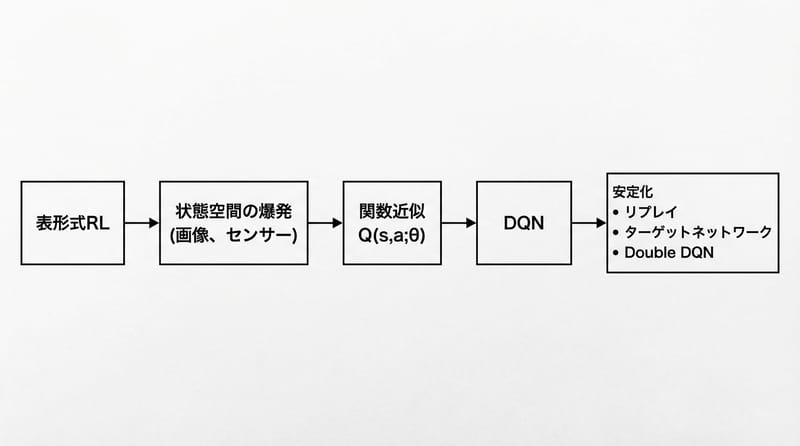
テーブルでQ値を管理する強化学習は、小さい環境だと強いけど、画像入力みたいな現実っぽい状態が来た瞬間に詰む。
結論:関数近似(ニューラルネットなど)でQ(s,a;θ)を学習し、DQNは経験再生・ターゲットネット・Double DQNで不安定さを抑えながら高次元入力に対応する。
- テーブルが壊れる理由:状態がデカすぎ、連続値、二度と同じ状態が来ない
- 置き換えるもの:Q(s,a) → Q(s,a;θ)(モデルが推定)
- DQNの芯:Q-learning + ニューラルネット + ε-greedy
- 安定化の三点セット:Experience Replay / Target Network / Double DQN
- 現場で見る落とし穴:発散、過大評価、忘却、データの偏り
テーブル方式が現実で折れる瞬間
Tabular SarsaやTabular Q-learningは、状態数が有限で小さいときだけ「全部のマス」を覚えられます。
状態が高解像度画像やセンサ時系列になると、状態空間が巨大か連続になり、表に保存も訪問もできません。
グリッドワールド。おもちゃの迷路。そこだと気持ちいいくらい動く。
でもカメラ付きロボット。株価みたいなノイズだらけの信号。
一回しか来ない状態、普通にある。いや、ほとんどそれ。
何が起きる?表の「穴」だらけになります。穴が埋まる前に時間が尽きる。
あと、状態が連続値だと「この値の行どこ?」ってなる。
マジで。そこが壁。
「全部覚える」から「だいたい当てる」に切り替えた瞬間、強化学習は現実のサイズに入ってくる。
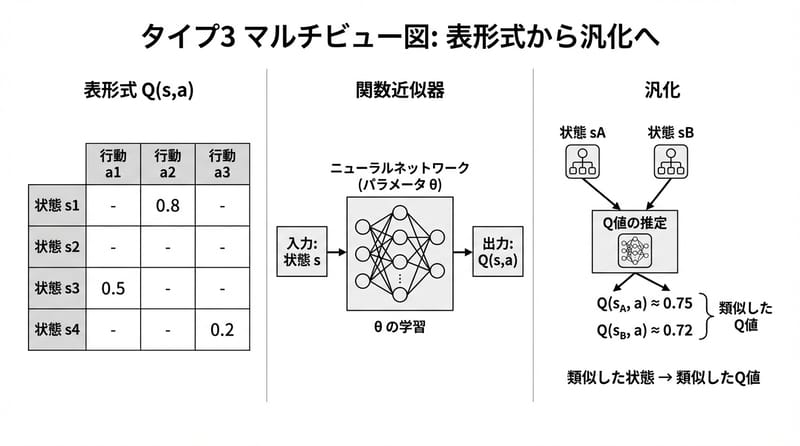
関数近似って、要は“値を予測する癖”を作る話
関数近似は、Q(s,a)をテーブルで保持せず、パラメータθを持つモデルでQ(s,a;θ)として推定します。
このモデルはTDターゲット(Bellman方程式由来)に合わせて、勾配降下法で重みを更新します。
名前が難しい。関数近似。近似って何だよってなる。
でもやってること、わりと素朴。
やりたいこと:見たことない状態でも、似てるなら似た値を返す。そういう癖をモデルに仕込む。
画像ならCNN。センサならMLPでもRNNでも、そこは設計。
ここで一個だけ、ちょっと現場っぽい話。
似た状態を「似た」と見なす表現が弱いと、学習が雑になる。
逆に表現が強いと、サンプル少なくても伸びる。たまに、びっくりするくらい。
増えるメリット:
- 一般化:似た状態へ値を広げられる
- サンプル効率:同じ状態を何回も踏まなくていい
- 高次元対応:画像、時系列、でかいベクトル
増える厄介:
- 表現がズレると、予測もズレる
- 更新が干渉して、別のところを壊す(catastrophic forgetting)
- ブートストラップ+非線形で発散しやすい
猫の記憶喪失、みたいな名前だけど笑えない。
昨日できてた行動が、今日できない。普通にある。
DQNは「Q-learningをニューラルネットに乗せたやつ」…だけじゃない
Deep Q-Network(DQN)は、ニューラルネットでQ(s,a;θ)を近似し、ε-greedyで行動し、TD誤差を損失として最適化するQ-learning系アルゴリズムです。
DQNは高次元入力(Atariのピクセルなど)から行動価値を学べる一方、学習が不安定になりやすいので安定化の仕掛けが必須です。
DQNって聞くと、なんか全部すごそうに見える。
でも中身は、割と筋肉質。
流れ:
- 状態sをネットに入れる
- 各行動aのQ値をまとめて出す
- ε-greedyで行動を選ぶ(たまにランダム)
- 報酬rと次状態s'を受け取る
- Bellmanっぽいターゲットでズレ(TD誤差)を作る
- 勾配降下法で損失を下げる
ここで、ちょっと嫌な話。
自分の予測で自分を更新する。ブートストラップ。
小さい誤差が、雪だるまになる。うわってなる。
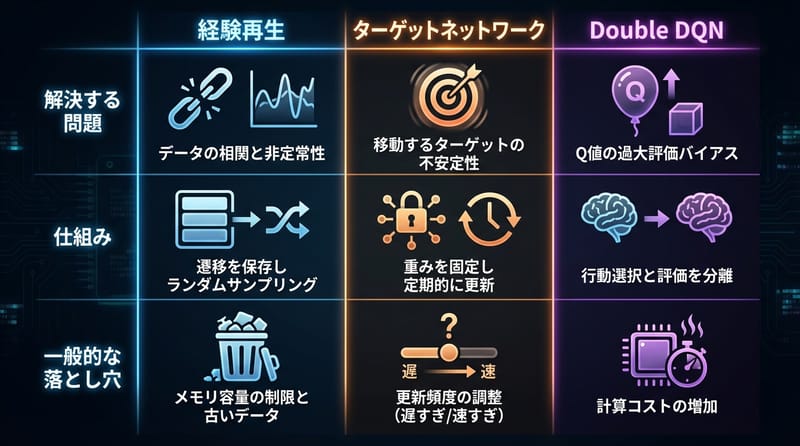
不安定さを止める“三点セット”:経験再生・ターゲットネット・Double DQN
Experience Replayは相関の強い連続経験を崩して再利用し、Target Networkは動く目標を固定し、Double DQNはQ値の過大評価を減らします。
この3つはDQN系の実装で事実上の標準になっており、発散や振動を抑えるための現実的な処方箋です。
リプレイバッファに経験(s,a,r,s')を貯める。
そこからランダムにミニバッチを引く。
連続データの偏りが薄まる。過去も何度も噛める。
地味だけど効く。ほんとに。
2) Target Network(ターゲットネット)
ターゲット計算用に別ネットQ_targetを持つ。
メインネットの重みをCステップごとにコピーする。
目標がしばらく動かない。追いかけっこが止まる。
3) Double DQN
最大値を取るときの「選ぶ」と「評価する」を分けます。
メインネットで次の行動を選ぶ。
ターゲットネットでその行動を評価する。
過大評価が減る。変に強気な学習が落ち着く。
ここ、よく誤解されるんだけど。
Double DQNは「性能を爆上げする魔法」じゃない。
変なバイアスを減らす。そういう性格。
DQNの怖さは賢さじゃなくて、ちょっとした誤差が増幅する速さにある。
日本でやる人向け:実装ツールと“買う場所”の避雷(地味に大事)
深層強化学習のDQN実装はPyTorchやTensorFlowで組めますが、再現性と評価にはGymnasiumやStable-Baselines3のような標準ツールが便利です。
学習の安定性は平均報酬だけでなく、TD誤差の推移、Q値のスケール、リプレイバッファの分布も見て判断します。
ここから急に生活感が出る。ごめん。
でも「どこで始めるか」って、沼を避ける鍵。
使う道具(具体名だけ置く):
- PyTorch:DQNのネットと最適化、手で触りやすい
- TensorFlow:チーム開発だと選ばれることも多い
- Gymnasium:環境APIの標準寄り、テストに便利
- Stable-Baselines3:DQN系も含めて実装の雛形が揃う
“進階指標”の見どころ:
- 平均報酬:上がってても安心しすぎない
- TD誤差:急に跳ねるとき、だいたい何か壊れてる
- Q値の絶対値:妙にでかいと過大評価の匂いがする
- 探索率εの履歴:下げるの早すぎると学習が固まる
で、ここが“内行人の避雷”ね。
日本の通路事情って、妙にクセがあるから。
避雷ガイド(日本ローカル):
- GPUが必要になったら、家電量販店で衝動買いしない:在庫で選ぶとだいたい後悔する
- 最初の一枚は中古もあり:じゃんぱら、ソフマップ系の中古、当たり外れはあるけど価格は落ち着く(だいたい2〜6万円帯の個体が見つかることも)
- 新品はECの価格差が激しい:Amazon、楽天、ヨドバシのポイント込みで体感が変わる。表示価格だけ見て突っ込むと損しやすい
- 学習用マシンを組むなら、秋葉原のパーツショップは強い:相談できる店員がいる店に当たると早い。外すと地獄
- クラウドは“短期”向き:Google Colabや各社GPUインスタンス、長時間回すと請求で目が覚める
価格は日々動く。そこはもう、波。
財布を守って。ほんと。
公式っぽい情報の当たりどころ:DeepMindのDQN論文(Nature 2015)とか、Gymnasiumのドキュメントとか。
一次情報は、冷たいけど強い。
最後に、これだけ覚えて帰って:スケールの鍵は“表を捨てる勇気”
強化学習を現実のサイズに持ち込むには、関数近似で一般化し、DQNの安定化手法で発散を抑える設計が必要です。
平均報酬だけで安心せず、TD誤差やQ値スケール、探索率の推移を一緒に見て学習の健康診断をします。
ここまで読んだ人、えらい。
低エネルギーで書いてる私が言うのも変だけど、えらい。
小さな挑戦、出すね。
今日か明日でいい。
Gymnasiumの簡単な環境を一つ選んで、DQNを回す。
そしてログに「平均報酬」「TD誤差」「Q値の最大値」を並べて、1回だけ眺める。
変な跳ね方をしたら、それがスタート地点。
怖い?うん、分かる。
でも、そこからが面白い。
※教育目的の一般情報です。実運用の設計や安全性評価は、用途と環境に合わせて専門家レビューや追加検証が必要です。


