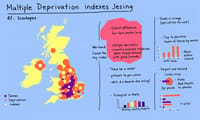
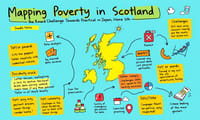
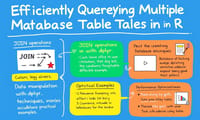
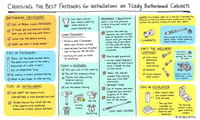
group_mapとgroup_splitで遊んだあの日~dplyr 0.8.0との格闘記~
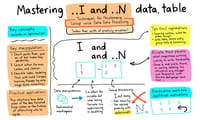
dplyrのgroup_mapとgroup_split、最近よく見かける気がする。どっちもグループ化したデータに何かするやつだけど、使い所は微妙に違うみたい。group_byでoriginごとに分けてからgroup_split使うと、三つぐらいリストになって返ってきた。細かい数は忘れたけど、一個あたりだいたい十万件以上入ってて割と大きめ。group_keysとかいう関数でグループ名確認できるんだっけ?なんとなく思い出す。
一方でgroup_mapはグループごとの処理を地味に書ける感じかな。例えば最初の五行だけ抜き出す適当な関数作ったら、それぞれのoriginから五行ずつ返してくれる、と。全部合わせても二十行にも満たないぐらいだったと思う。でもsplitした後でmapやろうとしても怒られた記憶がある、型が違うんだろうな。
正直、purrrとかと組み合わせない限りgroup_splitのありがたみはそんな大きくないような…。細かい挙動はいまだによく分かってないところも多いし、そのうちまた試すかもしれない。
一方でgroup_mapはグループごとの処理を地味に書ける感じかな。例えば最初の五行だけ抜き出す適当な関数作ったら、それぞれのoriginから五行ずつ返してくれる、と。全部合わせても二十行にも満たないぐらいだったと思う。でもsplitした後でmapやろうとしても怒られた記憶がある、型が違うんだろうな。
正直、purrrとかと組み合わせない限りgroup_splitのありがたみはそんな大きくないような…。細かい挙動はいまだによく分かってないところも多いし、そのうちまた試すかもしれない。
本段の参照元: https://www.johnmackintosh.net/blog/2019-02-28-first-look-at-mapping-and-splitting-in-dplyr/
日本語圏で広める難しさ~ドキュメント不足と文化ギャップとの戦い~
dplyrの関数を使っていて、日本のデータサイエンスコミュニティでは、これらの微妙な違いを理解するのに苦労することがあります。技術的な文脈で、関数の細かい挙動を説明する際、専門用語の解釈や翻訳の難しさに直面します。特に、プログラミングの専門的な nuance を正確に伝えるのは、日本語の曖昧さや婉曲的な表現のため、チャレンジングです。
また、オープンソースコミュニティでの技術的な議論では、英語と日本語の間の文化的・言語的ギャップも障壁となります。関数の微妙な使い分けを説明する際、直訳では伝わりにくく、適切な比喩や説明が求められるため、コミュニケーションに追加の労力が必要となります。
また、オープンソースコミュニティでの技術的な議論では、英語と日本語の間の文化的・言語的ギャップも障壁となります。関数の微妙な使い分けを説明する際、直訳では伝わりにくく、適切な比喩や説明が求められるため、コミュニケーションに追加の労力が必要となります。